Kā datu bāzes administratoriem mums ir jābūt apsēstiem ar rīkiem un metodēm datu bāzes veiktspējas uzlabošanai.
Programmā PostgreSQL mums ir piekļuve komandai EXPLAIN ANALYZE, kas ļauj analizēt noteiktā datu bāzes vaicājuma izpildes plānu un veiktspēju. Komanda atgriež detalizētu informāciju par to, kā datu bāzes programma apstrādā vaicājumu. Tas ietver veikto darbību secību, aptuvenās vaicājumu izmaksas, izpildes laiku un daudz ko citu.
Pēc tam mēs varam izmantot šo informāciju, lai identificētu datu bāzes vaicājumus, kā arī identificētu un novērstu iespējamās veiktspējas vājās vietas.
Šajā apmācībā ir apskatīts, kā lietot PostgreSQL komandu EXPLAIN ANALYZE, lai skatītu un optimizētu vaicājuma veiktspēju.
PostgreSQL IZSKAIDROT ANALĪZI
Komanda ir diezgan vienkārša. Pirmkārt, mums ir jāpievieno komanda EXPLAIN ANALYZE vaicājuma, kuru vēlamies analizēt, sākumā.
Komandas sintakse ir šāda:
IZSKAIDROT ANALĪZIKad esat izpildījis komandu, PostgreSQL atgriež detalizētu izvadi par sniegto vaicājumu.
Izpratne par vaicājuma EXPLAIN ANALYZE izvadi
Kā minēts, kad mēs palaižam komandu EXPLAIN ANALYZE, PostgreSQL ģenerē detalizētu ziņojumu par vaicājumu plānu un izpildes statistiku.
Izvade sastāv no kolonnu kopas, kas satur noderīgu informāciju. Rezultātā iegūtās kolonnas ir tādas, kā parādīts ar to attiecīgo nozīmi:
JAUTĀJUMA PLĀNS – Šajā kolonnā tiek parādīts norādītā vaicājuma izpildes plāns. Izpildes plāns attiecas uz darbību secību, ko datu bāzes dzinējs veic, lai veiksmīgi pabeigtu vaicājumu.
PLĀNS – Otrā kolonna ir kolonna PLĀNS. Tas satur katras izpildes plāna darbības vai soļa tekstuālu attēlojumu. Atkal, katra darbība ir atkāpe, lai norādītu operāciju hierarhiju.
KOPĒJĀS IZMAKSAS – Kopējo izmaksu kolonna parāda vaicājuma aptuvenās kopējās izmaksas. Izmaksas attiecas uz relatīvu mērījumu, ko datu bāzes vaicājumu plānotājs izmanto, lai noteiktu optimālo izpildes plānu.
FAKTISKĀS RINDAS – Šajā kolonnā ir norādīts precīzs rindu skaits, kas tiek apstrādātas katrā vaicājuma izpildes posmā.
FAKTISKAIS LAIKS – Šajā slejā tiek parādīts katras darbības faktiskais laiks, kas ietver gan operācijas izpildes laiku, gan resursiem patērēto laiku.
PLĀNOŠANAS LAIKS – Šajā kolonnā ir parādīts laiks, kas vaicājumu plānotājam nepieciešams, lai ģenerētu izpildes plānu. Tas ietver kopējo vaicājuma optimizācijas un plāna ģenerēšanas laiku.
IZPILDES LAIKS – Šajā kolonnā ir parādīts kopējais vaicājuma izpildes laiks. Tas ietver arī plānošanai pavadīto laiku un vaicājuma izpildes laiku.
PostgreSQL EXPLAIN ANALYZE Piemērs
Apskatīsim dažus pamata piemērus priekšraksta EXPLAIN ANALYZE izmantošanai.
1. piemērs: atlasiet paziņojumu
Izmantosim priekšrakstu EXPLAIN ANALYZE, lai parādītu vienkārša atlases priekšraksta izpildi programmā PostgreSQL.
Kad mēs palaižam iepriekšējo paziņojumu, mums vajadzētu iegūt šādu izvadi:
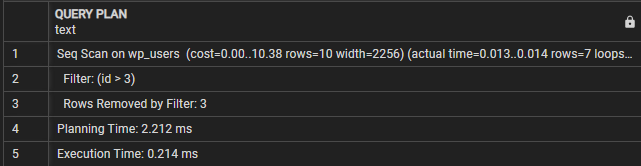
JAUTĀJUMA PLĀNS-------------------------------------------------- ------------------
Seq Scan on wp_users (maksa = 0,00..10,38 rindas = 10 platums = 2256) (faktiskais laiks = 0,009...0,010 rindas = 7 cilpas = 1)
Filtrs: (id > 3)
Filtra noņemtās rindas: 3
Plānošanas laiks: 0,995 ms
Izpildes laiks: 0,021 ms
(5 rindas)
Šajā gadījumā mēs varam redzēt, ka sadaļa Vaicājumu plāns norāda, ka vaicājums veic secīgu skenēšanu tabulā wp_users. Filtra līnija apzīmē nosacījumu, kas tiek izmantots iegūto rindu filtrēšanai.
Pēc tam mēs redzam 'Filtra noņemtās rindas', kas parāda rindu skaitu, kuras ir izslēgtas filtra nosacījuma dēļ.
Visbeidzot, izpildes laiks parāda kopējo vaicājuma izpildes laiku. Šajā gadījumā vaicājums aizņem 0,021 ms.
2. piemērs: pievienošanās analīze
Apskatīsim sarežģītāku vaicājumu, kas ietver SQL pievienošanos. Šim nolūkam mēs izmantojam Pagila paraugu datubāzi. Demonstrācijas nolūkos varat lejupielādēt un instalēt datu bāzes paraugu savā datorā.
Mēs varam veikt vienkāršu pievienošanos, kā parādīts tālāk:
izskaidrot analizēt SELECT f.titt, c.nameNO filmas f
JOIN film_category fc ON f.film_id = fc.film_id
JOIN kategorijai c ON fc.category_id = c.category_id;
Kad mēs palaižam doto vaicājumu, mums vajadzētu redzēt šādu izvadi:
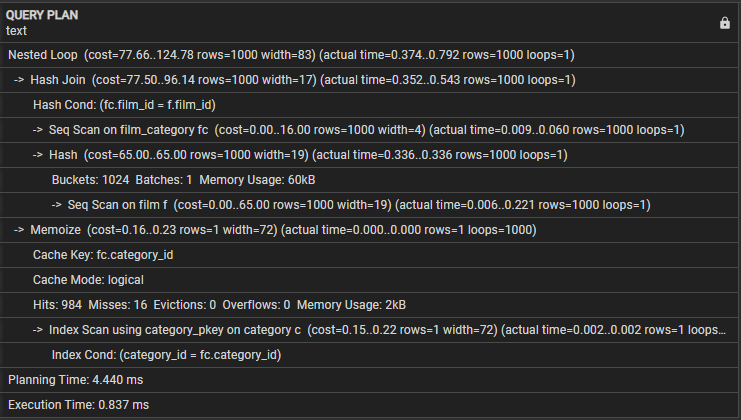
Izpētīsim šādu vaicājumu plānu:
- Ligzdota cilpa — tas norāda, ka savienojumam tiek izmantota ligzdotas cilpas savienojuma stratēģija.
- Hash Join — šī darbība savieno film_category un filmu tabulas, izmantojot Hash savienojuma algoritmu. Šīs operācijas izmaksas ir 77,50 un tiek lēstas 1000 rindu. Tomēr faktiskais šīs darbības laiks ir no 0,254 līdz 0,439 milisekundēm, un tā izgūst 1000 rindas.
- Hash Cond — tas norāda, ka savienojuma nosacījums izmanto jaukšanas savienojumu, lai filmu tabulās atbilstu kolonnām film_id un film_category kolonnām.
- Seq Scan on film_category — šī darbība veic secīgu skenēšanu tabulā film_category ar izmaksām 16,00 un aptuveni 1000 rindu. Faktiskais laiks, kas nepieciešams šai darbībai, ir no 0,008 līdz 0,056 milisekundēm, un tā izgūst 1000 rindas.
- Seq Scan on film — vaicājums veic secīgu skenēšanu filmu tabulā ar aptuvenajām un faktiskajām izmaksām un rindām šajā darbībā.
- Memoize — šī darbība kešatmiņā saglabā film_category un filmu tabulu savienojuma rezultātus turpmākai lietošanai.
- Kešatmiņas atslēga — tas norāda, ka kešatmiņas atslēga, kas tiek izmantota iegaumēšanai, ir balstīta uz sleju category_id no film_category.
- Kešatmiņas režīms — tas norāda, ka vaicājumā tiek izmantots loģiskās kešatmiņas režīms.
- trāpījumi, netrāpījumi, izlikšana, pārpilde — trīs rindiņas sniedz statistiku par kešatmiņu, trāpījumu skaitu, netrāpījumiem, izlikšanu un pārpildīšanu izpildes laikā. Šis bloks ietver arī atmiņas izmantošanu vaicājuma izpildes laikā.
- Indeksa skenēšana, izmantojot category_pkey — parāda darbību, kas veic indeksa skenēšanu kategoriju tabulā, izmantojot primārās atslēgas indeksu.
- Indeksa nosacījums — parāda, ka indeksa skenēšana ir balstīta uz nosacījumu, kas atbilst kategoriju tabulas kolonnai category_id.
- Plānošanas laiks — šī rinda parāda vaicājuma plānošanai nepieciešamo laiku, kas ir 3,005 milisekundes.
- Izpildes laiks — visbeidzot, šī rinda parāda kopējo vaicājuma izpildes laiku, kas ir 0,745 milisekundes.
Tur jums tas ir! Detalizēta informācija par vienkārša savienojuma izpildi programmā PostgreSQL.
Secinājums
Jūs atklājāt priekšraksta EXPLAIN ANALYZE jaudu un lietojumu programmā PostgreSQL. Paziņojums EXPLAIN ANALYZE ir spēcīgs vaicājumu analīzes un optimizācijas rīks. Izmantojiet šo rīku, lai izveidotu efektīvus un mazāk resursietilpīgus vaicājumus.