Šī rokasgrāmata ilustrēs entītiju atmiņas izmantošanas procesu LangChain.
Kā lietot entītiju atmiņu programmā LangChain?
Entītija tiek izmantota, lai saglabātu atmiņā saglabātos galvenos faktus, lai tos izņemtu, kad cilvēks to jautā, izmantojot vaicājumus/uzvednes. Lai uzzinātu entītiju atmiņas izmantošanas procesu programmā LangChain, vienkārši apmeklējiet šo rokasgrāmatu:
1. darbība: instalējiet moduļus
Vispirms instalējiet LangChain moduli, izmantojot komandu pip, lai iegūtu tā atkarības:
pip instalēt langchain
Pēc tam instalējiet OpenAI moduli, lai iegūtu tā bibliotēkas LLM un tērzēšanas modeļu veidošanai:
pip install openai
Iestatiet OpenAI vidi izmantojot API atslēgu, ko var iegūt no OpenAI konta:
imports tu
imports getpass
tu . aptuveni [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API atslēga:' )
2. darbība. Entītijas atmiņas izmantošana
Lai izmantotu entītijas atmiņu, importējiet vajadzīgās bibliotēkas, lai izveidotu LLM, izmantojot OpenAI() metodi:
no langchain. llms imports OpenAIno langchain. atmiņa imports ConversationEntityMemory
llm = OpenAI ( temperatūra = 0 )
Pēc tam definējiet atmiņa mainīgais, izmantojot metodi ConversationEntityMemory(), lai apmācītu modeli, izmantojot ievades un izvades mainīgos:
atmiņa = ConversationEntityMemory ( llm = llm )_ievade = { 'ievade' : 'Džo ir Roots ir īstenojis projektu' }
atmiņa. load_memory_variables ( _ievade )
atmiņa. save_context (
_ievade ,
{ 'izeja' : 'Lieliski! Kas tas par projektu?' }
)
Tagad pārbaudiet atmiņu, izmantojot vaicājumu/uzvedni ievade mainīgais, izsaucot metodi load_memory_variables():
atmiņa. load_memory_variables ( { 'ievade' : 'kas ir sakne' } ) 
Tagad sniedziet vairāk informācijas, lai modelis varētu pievienot atmiņā vēl dažas entītijas:
atmiņa = ConversationEntityMemory ( llm = llm , return_messages = Taisnība )_ievade = { 'ievade' : 'Džo ir Roots ir īstenojis projektu' }
atmiņa. load_memory_variables ( _ievade )
atmiņa. save_context (
_ievade ,
{ 'izeja' : 'Lieliski! Kas tas par projektu' }
)
Izpildiet šo kodu, lai iegūtu izvadi, izmantojot atmiņā saglabātās entītijas. Tas ir iespējams, izmantojot ievade satur uzvedni:
atmiņa. load_memory_variables ( { 'ievade' : 'kas ir Džo' } ) 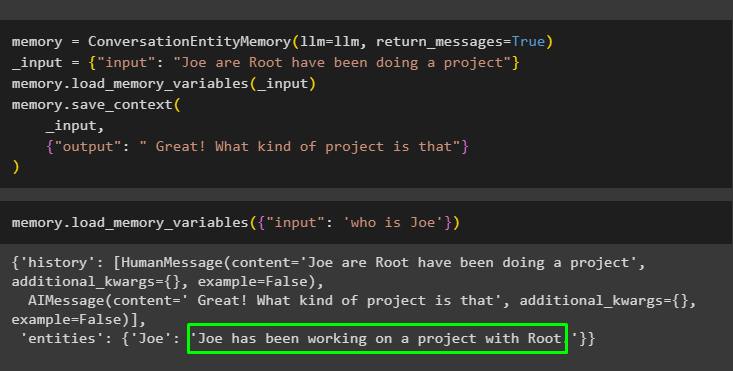
3. darbība. Entītijas atmiņas izmantošana ķēdē
Lai izmantotu entītijas atmiņu pēc ķēdes izveidošanas, vienkārši importējiet vajadzīgās bibliotēkas, izmantojot šādu koda bloku:
no langchain. ķēdes imports Sarunu ķēdeno langchain. atmiņa imports ConversationEntityMemory
no langchain. atmiņa . pamudināt imports ENTITY_MEMORY_CONVERSATION_TEMPLATE
no pidantisks imports Pamatmodelis
no rakstot imports Saraksts , Dikts , Jebkurš
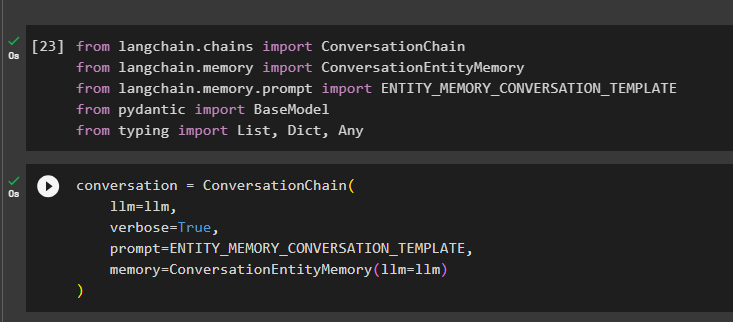
Izveidojiet sarunas modeli, izmantojot ConversationChain() metodi, izmantojot tādus argumentus kā llm:
saruna = Sarunu ķēde (llm = llm ,
runīgs = Taisnība ,
pamudināt = ENTITY_MEMORY_CONVERSATION_TEMPLATE ,
atmiņa = ConversationEntityMemory ( llm = llm )
)
Izsauciet sarunu.predict() metodi ar ievadi, kas inicializēta ar uzvedni vai vaicājumu:
saruna. prognozēt ( ievade = 'Džo ir Roots ir īstenojis projektu' ) 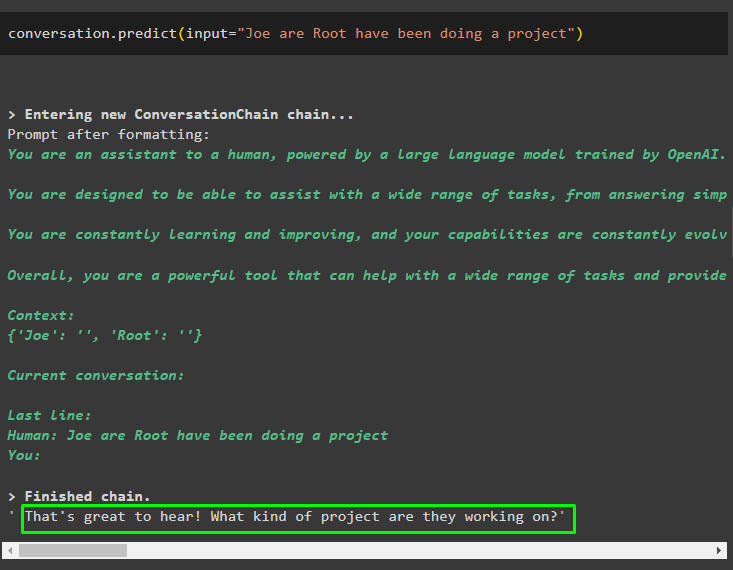
Tagad iegūstiet atsevišķu izvadi katrai entītijai, kas apraksta informāciju par to:
saruna. atmiņa . entity_store . veikals 
Izmantojiet modeļa izvadi, lai sniegtu ievadi, lai modelis varētu saglabāt vairāk informācijas par šīm entītijām:
saruna. prognozēt ( ievade = 'Viņi mēģina Langchain pievienot sarežģītākas atmiņas struktūras' ) 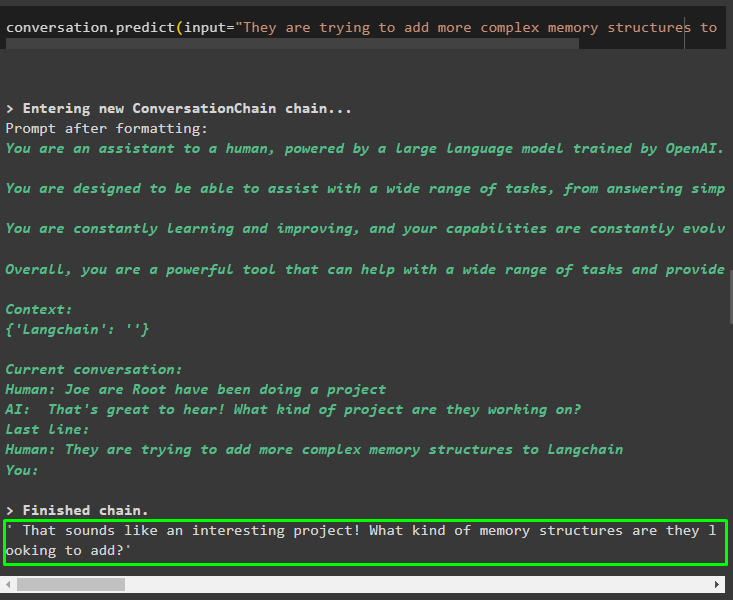
Kad esat norādījis informāciju, kas tiek glabāta atmiņā, vienkārši uzdodiet jautājumu, lai iegūtu konkrētu informāciju par entītijām:
saruna. prognozēt ( ievade = 'Ko jūs zināt par Džo un Rootu' ) 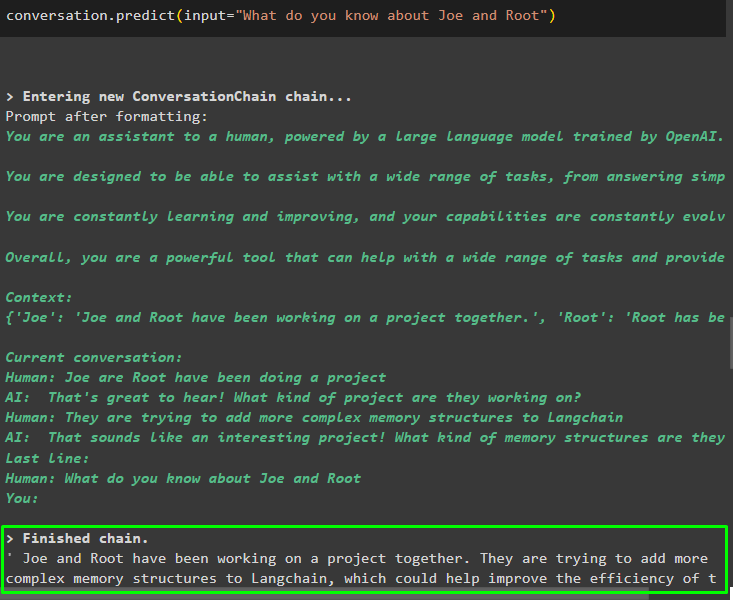
4. darbība. Atmiņas veikala pārbaude
Lietotājs var tieši pārbaudīt atmiņas krātuves, lai iegūtu tajos saglabāto informāciju, izmantojot šādu kodu:
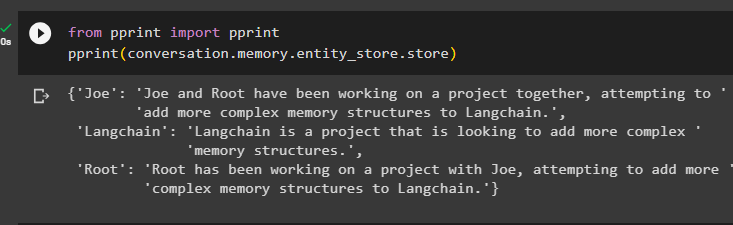
no drukāt imports drukātdrukāt ( saruna. atmiņa . entity_store . veikals )
Sniedziet vairāk informācijas, kas jāsaglabā atmiņā, jo vairāk informācijas sniedz precīzākus rezultātus:
saruna. prognozēt ( ievade = 'Root ir nodibinājis uzņēmumu ar nosaukumu HJRS' ) 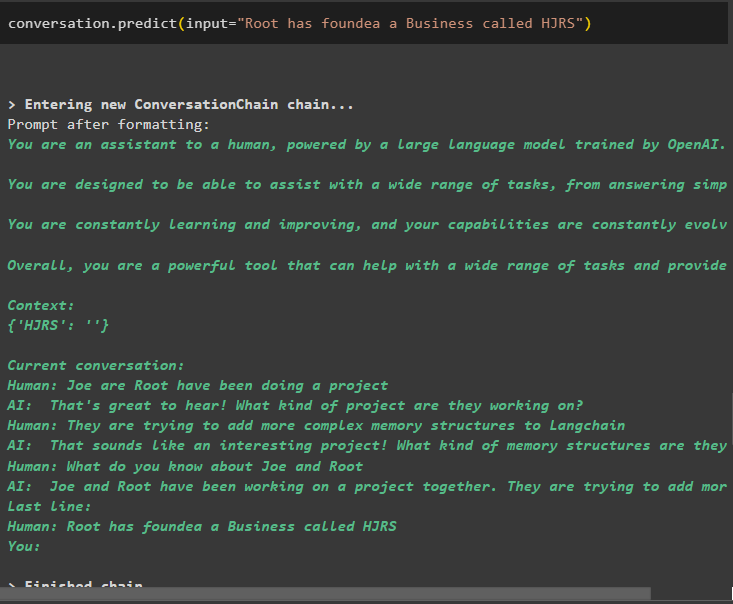
Izņemiet informāciju no atmiņas krātuves pēc papildu informācijas pievienošanas par entītijām:
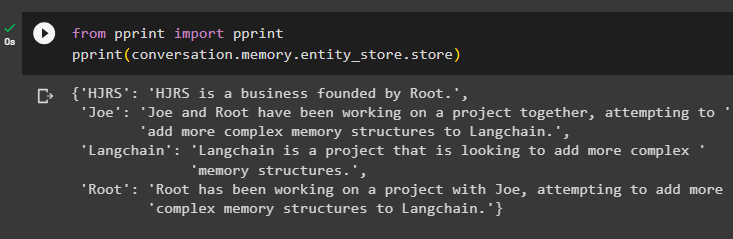
no drukāt imports drukātdrukāt ( saruna. atmiņa . entity_store . veikals )
Atmiņā ir informācija par vairākām entītijām, piemēram, HJRS, Joe, LangChain un Root:
Tagad iegūstiet informāciju par konkrētu entītiju, izmantojot ievades mainīgajā definēto vaicājumu vai uzvedni:
saruna. prognozēt ( ievade = 'Ko jūs zināt par sakni' ) 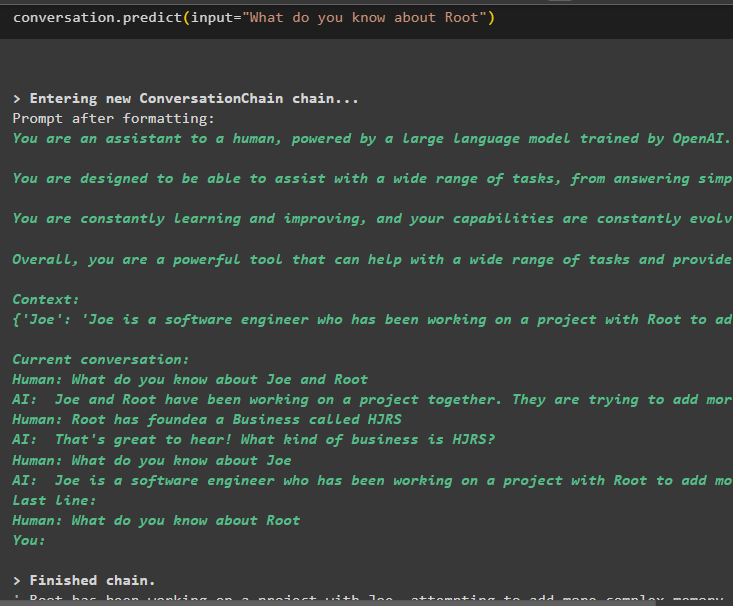
Tas ir viss par entītiju atmiņas izmantošanu, izmantojot LangChain sistēmu.
Secinājums
Lai izmantotu entītijas atmiņu programmā LangChain, vienkārši instalējiet nepieciešamos moduļus, lai pēc OpenAI vides iestatīšanas importētu bibliotēkas, kas nepieciešamas modeļu veidošanai. Pēc tam izveidojiet LLM modeli un saglabājiet entītijas atmiņā, sniedzot informāciju par entītijām. Lietotājs var arī iegūt informāciju, izmantojot šīs entītijas, un veidot šīs atmiņas ķēdēs ar maisīto informāciju par entītijām. Šajā ziņojumā ir aprakstīts entītijas atmiņas izmantošanas process LangChain.