Katru dienu tiek apkopoti milzīgi dati, un lielo datu pārvaldība ir vissvarīgākais Elasticsearch dzinēja lietošanas gadījums. Dati tiek glabāti analītikas datu bāzē reāllaikā, un lietotājam ir atļauts iegūt datus, lai, izmantojot vaicājumus, atrastu no tiem noderīgas zināšanas. Lietotājs var lietot vaicājumus, lai atrastu datus no vairākiem indeksiem un parādītu tos vienā segmentā no relāciju datu bāzes.
Šajā rokasgrāmatā Elasticsearch apkopojumi tiks izskaidroti ar piemēriem, izmantojot dažādus apkopojumus.
Kas ir Elasticsearch agregācija?
Programmā Elasticsearch apkopošana ir lauku apvienošanas vai grupēšanas process, lai iegūtu informāciju no relāciju datu bāzes. Elasticsearch apkopojumu var uzskatīt par GRUPA PĒC KLAUZAS vai AGREGĀTS() funkcija SQL valodā.
Kā izmantot Elasticsearch agregāciju?
Lai izmantotu apkopojumu programmā Elasticsearch, lietotājam ir jābūt pamatzināšanai par savu datu bāzi. Izpētīsim sintaksi un tās praktisko ieviešanu:
Sintakse
Lai atrastu datus no datu bāzes, Elasticsearch dzinēja apkopojuma sintakse, kā norādīts tālāk:
'aggs' : {'apkopošanas_nosaukums' : {
'apkopošanas_veids' : {
'lauks' : 'dokumenta_lauka_nosaukums'
}
Iepriekš minētie fragmenti:
-
- Tas izmanto ' aggs ” atslēgvārds, kas izskaidro apkopošanas lietojumu vaicājumā.
- The agregācijas_nosaukums iestata lietotājs saskaņā ar nepieciešamo informāciju.
- Pēc tam, agregācijas_veids tiek izmantots datu iegūšanai.
- Pēdējā rindā tiek izmantots lauks atslēgvārds, kam seko dokumenta atribūta nosaukums.
1. piemērs: Kibana paraugdatu apkopošana
Šajā sadaļā ir izskaidrota apkopošana, izmantojot piemēru, izmantojot paraugdatus no Kibana, vispirms izveidojot savienojumu ar to. Pēc tam vienkārši dodieties iekšā Izstrādātāju rīki ”, meklējot to meklēšanas joslā un noklikšķinot uz tā:
Iegūstiet datus no datu paraugiem
Vienkārši izmantojiet šo komandu, lai iegūtu datus no ' kibana_sample_data_logs ” indekss Dev Tools konsolē:
GŪT / kibana_sample_data_logs / _Meklēt
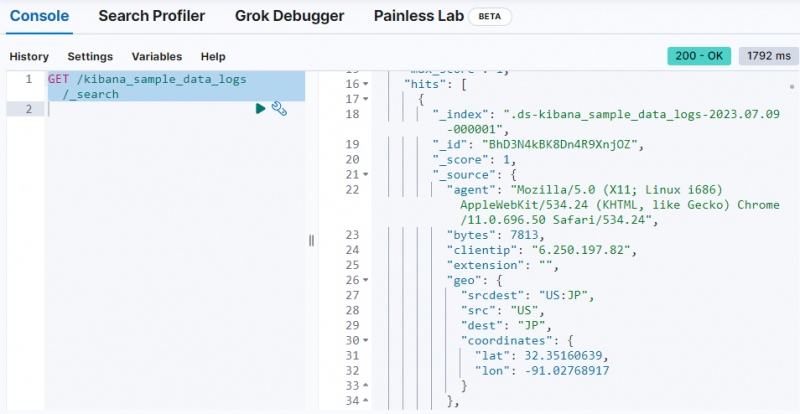
Izvade parāda, ka dati ir iegūti no ' kibana_sample_data_logs ” indekss.
Šis kods izmanto a GŪT pieprasījums uz ' kibana_sample_data_log ”, lai meklētu tajā, izmantojot vērtību_skaita apkopojumu klienta tips ” lauks:
GŪT / kibana_sample_data_logs / _Meklēt{ 'Izmērs' : 0 ,
'aggs' : {
'ip_count' : {
'vērtības_skaits' : {
'lauks' : 'klients'
}
}
}
}
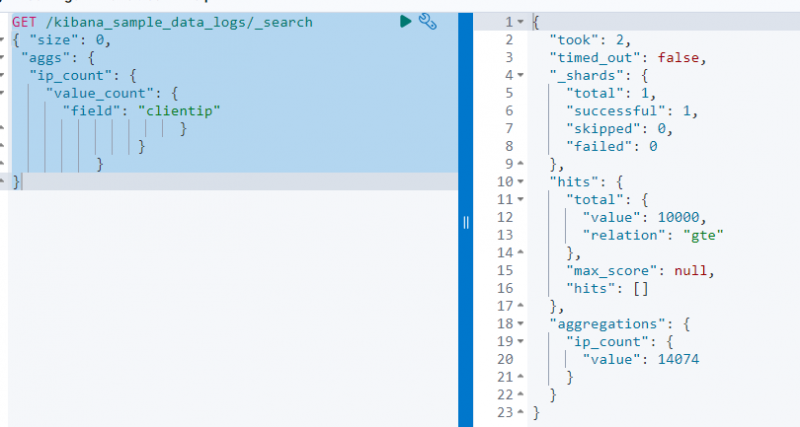
Iepriekš redzamajā ekrānuzņēmumā ir parādīts apkopojums klienta tips lauks ar vērtību 14074 .
Svarīgi apkopojumi
Tālāk ir minēti daži svarīgi apkopojumi, kas tiek izmantoti, lai efektīvi atrastu datus no datu bāzes.
Šajos piemēros ir izskaidroti iepriekš minētie apkopojumi, izmantojot GŪT pieprasījums no ' kibana_sample_data_ecommerce ” indekss:
Kardinalitātes apkopošana
Šis kods izmanto ' kardinalitāte ' apkopojums uz ' sku ” laukā no e-komercijas datiem. Palaižot šo kodu, tiks iegūts vienas vērtības apkopojums, lai iegūtu unikālos SKU no Elasticsearch datu bāzes:
GŪT / kibana_sample_data_ecommerce / _Meklēt{
'Izmērs' : 0 ,
'aggs' : {
'unikāls_skus' : {
'kardinalitāte' : {
'lauks' : 'sku'
}
}
}
}
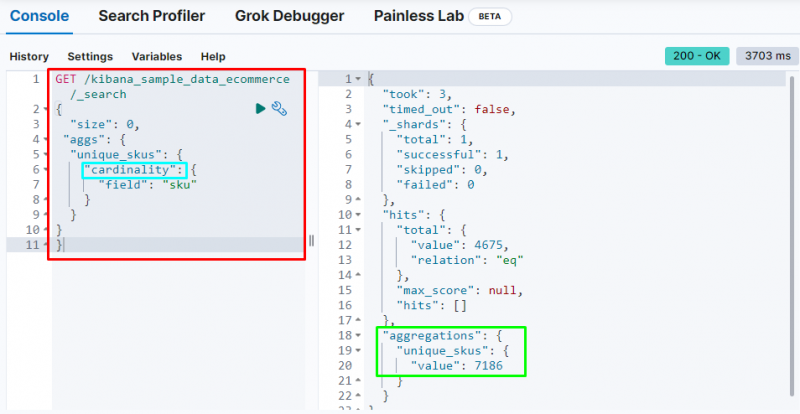
Tas parāda kardinalitāte agregācijas atrašana 7186 vērtības no indeksa.
Statistikas apkopošana
Vēl viens svarīgs apkopojums ir ' statistika ' apkopojums, kas tiek izmantots, lai iegūtu ' skaitīt ”, “ min ”, “ maks ”, “ vid ', un ' summa ' statistika no ' kopējais_daudzums ” lauks:
GŪT / kibana_sample_data_ecommerce / _Meklēt{
'Izmērs' : 0 ,
'aggs' : {
'quantity_stats' : {
'statistika' : {
'lauks' : 'kopējais_daudzums'
}
}
}
}
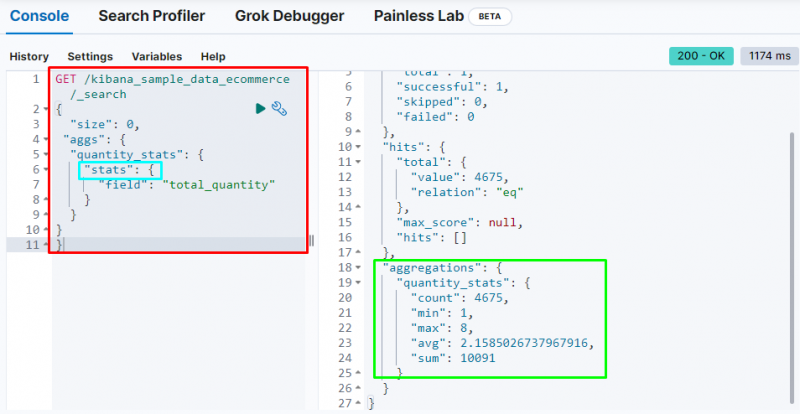
Iepriekš redzamajā ekrānuzņēmumā ir parādīta statistika izvadē no “ kopējais_daudzums ” lauks.
Filtru apkopošana
Filtru apkopošana tiek izmantota, lai filtrētu datus, pamatojoties uz terminu vai frāzi no datu bāzes, jo to satur šāds kods:
GŪT / kibana_sample_data_ecommerce / _Meklēt{ 'Izmērs' : 0 ,
'aggs' : {
'filtrs_apkopojums' : {
'filtrs' : {
'jēdziens' : {
'lietotājs' : 'edijs' } } ,
'aggs' : {
'cena_vid.' : {
'vid.' : {
'lauks' : 'produkti.cena' } }
} } } }
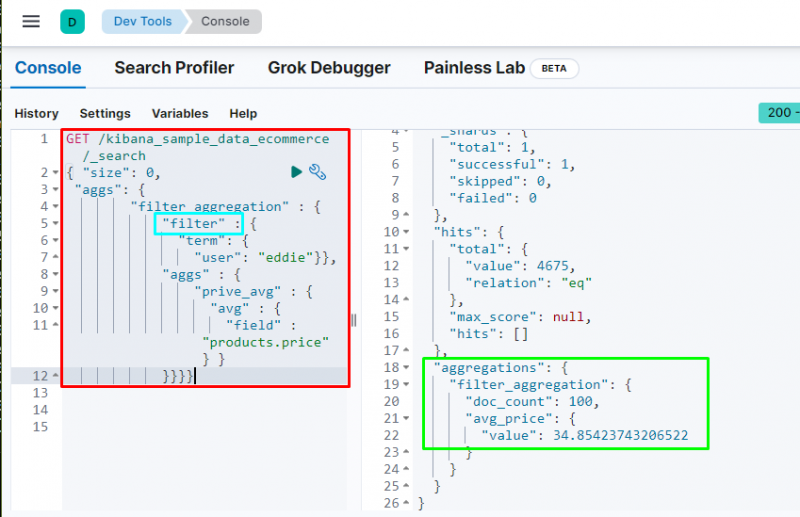
Koda izpilde filtrēs datus, pamatojoties uz ' Edijs ” lietotājs un parāda iegādāto preču vidējo cenu. Iepriekš redzamais ekrānuzņēmums parāda, ka lietotājs ir atradis 100 reizes no datiem un vērtību no vid _ cena apkopošana.
Termiņu apkopošana
Termins apkopošana izveido segmentu un saglabā datus no lauka segmentā, un tālāk norādītais kods izmanto ' lietotājs ” lauks, lai saglabātu savus datus spainī:
GŪT / kibana_sample_data_ecommerce / _Meklēt{
'Izmērs' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'noteikumi' : {
'lauks' : 'lietotājs'
}
}
}
}
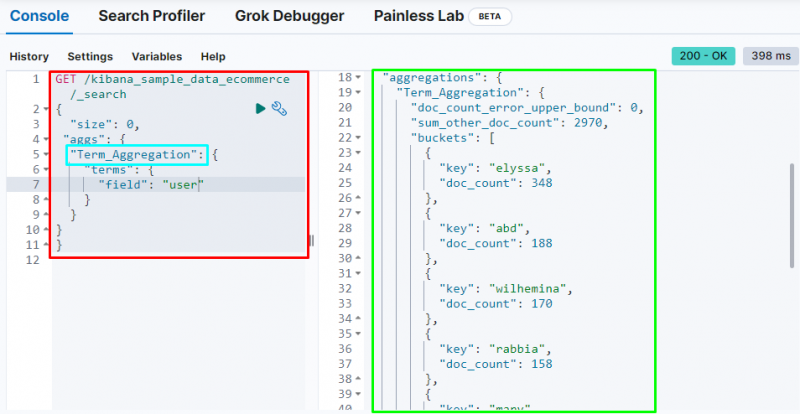
Nākamajā ekrānuzņēmumā ir redzams, ka termina apkopošana ir izveidojusi segmentus katram lietotājam un viņa dokumentu skaitam.
Tas viss attiecas uz Elasticsearch apkopošanu un dažādiem svarīgiem apkopojumiem.
Secinājums
Programmā Elasticsearch apkopojums tiek izmantots, lai iegūtu datus no apkopotajiem dokumentiem, un šie dokumenti tiek iegūti no noteikta lauka. Ir daži svarīgi apkopojumi, kas tiek izmantoti, lai no indeksiem gūtu noderīgu ieskatu. Šajā rokasgrāmatā ir izskaidrota Elasticsearch apkopošana un parādīts Elasticsearch agregācijas izmantošanas process.