Ķīlis (Knowledge Extraction, pamatojoties uz Evolutionary Learning) ir Java programmatūras rīks, kas specializējas evolūcijas algoritmu ieviešanā. Tā kā tas ir atvērts avots, tas nodrošina plašu zināšanu atklāšanas algoritmu klāstu, ko var izmantot eksperimentos, kas nodrošina datu ieguves un analīzes kopienu. Tas nodrošina vienkāršu un viegli lietojamu grafisko lietotāja interfeisu, kas ievērojami samazina šī rīka kopējo sarežģītību. Lielākajai daļai līdzīgu rīku tirgū ir nepieciešams, lai lietotāji mijiedarbotos ar tiem, rakstot kodu, savukārt Keel šo prasību noņem, nodrošinot intuitīvu GUI, ko var izmantot gan iesācēji, gan eksperti.
Keel nodrošina plašu dažādu uz skaitļošanas inteliģenci balstītu algoritmu klāstu, tostarp klasifikāciju, regresiju, pazīmju izgūšanu, modeļu analīzi, klasterizāciju un daudz ko citu. Tā kā vispārējie modeļi ir iekļauti pašā lietojumprogrammā, Keel ir ļoti noderīgs rīks, lai veiktu pētniecisko datu analīzi neapstrādātām datu kopām. Tā vienkāršais vilkšanas un nomešanas interfeiss, kas savienots pārī ar vieglu funkcionalitātes izmantošanu, ļauj ātri un efektīvi veikt datu ieguves eksperimentus gan izglītības, gan pētniecības nolūkos. Tādi rīki kā Keel kļūst arvien populārāki to vienkāršotās pieejas dēļ citādi sarežģītām algoritmiskām praksēm.
Uzstādīšana
Ir divi galvenie instalēšanas veidi Ķīlis jebkurā Linux mašīnā. Pirmais ietver došanos uz Ķīļa tīmekļa lapa un lejupielādējot programmatūru no turienes. Otrajā, ko mēs ievērosim šajā instalēšanas rokasgrāmatā, ir nepieciešams lejupielādēt Keel, izmantojot wget lejupielādes rīks, kas pieejams Linux lietotājiem.
1. Mēs sākam ar iegūšanu wget mūsu Linux mašīnā.
Palaidiet šo komandu, lai lejupielādētu wget, izmantojot apt pakotņu pārvaldnieks:
$ sudo apt-get install wget
Jūs redzēsit līdzīgu termināļa izvadi:
2. Tagad, kad mums ir wget rīks, kas instalēts mūsu Linux mašīnā, mēs to izmantojam, lai lejupielādētu Ķīlis rīks.
Tas ir saite ko mēs pārejam uz wget.
Terminālī izpildiet šādu komandu:
$ wget http: // sci2s.ugr.es / ķīlis / programmatūra / prototipus / atvērtā versija / Programmatūra- 2018. gads -04-09.zip
Jums vajadzētu redzēt līdzīgu izvadi savā terminālī:
Kad Keel lejupielāde ir pabeigta, mēs varam turpināt instalēšanas atlikušo daļu.
3. Tagad mēs izņemam saspiesto failu, ko lejupielādējām iepriekšējā darbībā, izmantojot Linux Unzip rīku.
Palaidiet šādu komandu:
$ izņemiet rāvējslēdzēju Programmatūra- 2018. gads -04-09.zip
Jums vajadzētu redzēt līdzīgu izvadi terminālī:
4. Pārejiet uz mapi Keel, izpildot šādu komandu:
$ cd Programmatūra- 2018. gads -04-09 / dokumentus / eksperimentiem / KEEL / dist /
5. Lai sāktu instalēšanu, palaidiet šo komandu:
$ java - burka . / GraphInterKeel.jar
Tādējādi Keel vajadzētu būt pieejamam lietošanai savā Linux mašīnā.
Lietotāja rokasgrāmata
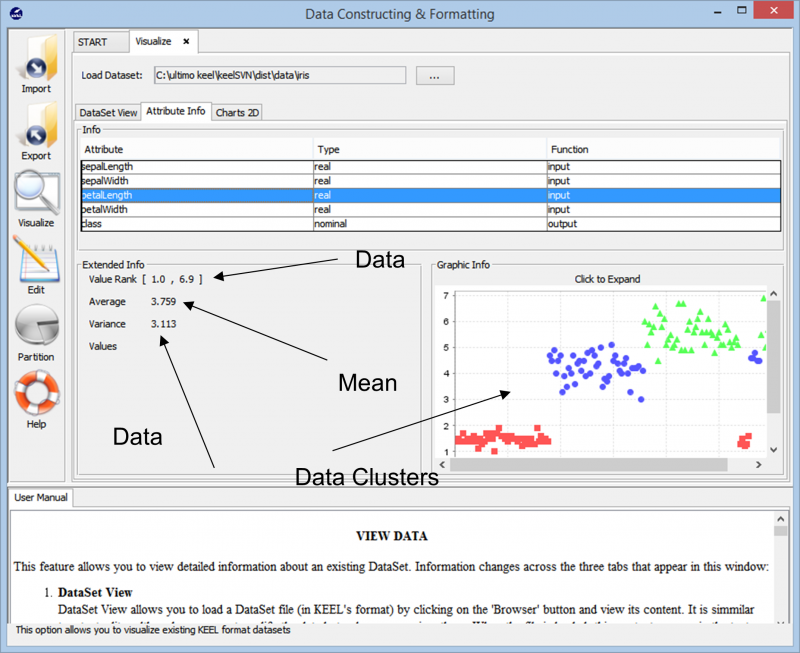
Mijiedarbojoties ar Ķīlis pieteikšanās ir patiešām vienkārša un vienkārša. Sāksim ar importēšanu Iris datu kopa mūsu darbvietā.
Kad mēs importējam datus, rīks parāda kopējo datu punkta klasterizāciju datu kopā. Tas arī parāda dažādas klases, kas atrodas datu kopā, kā arī pamatinformāciju, piemēram, skaitliskos diapazonus, ko šie datu punkti aptver, un kopējo dispersiju un vidējās vērtības, ko tas sniedz. Šī informācija ļauj lietotājiem labāk izprast, kā turpināt datu sagatavošanu jebkura veida datu analīzes uzdevumam.
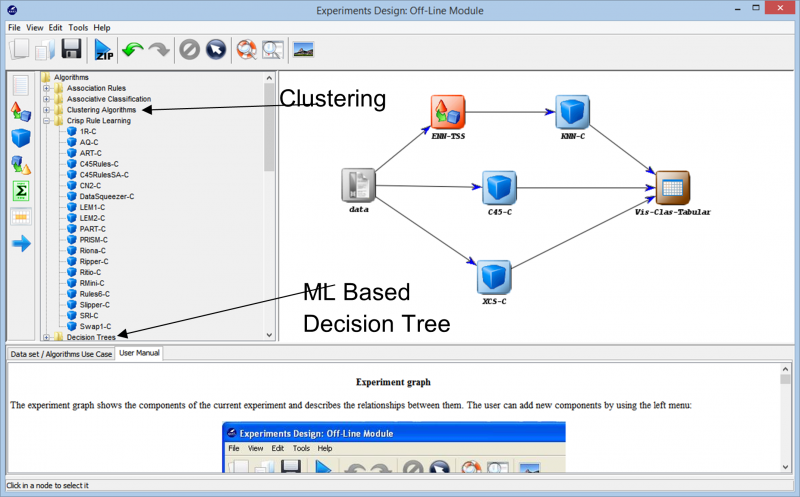
Turpinot eksperimentu, mēs saskaramies ar dažādām metodēm, kuras var izmantot, lai izveidotu eksperimentu ar jebkuru datu kopu. Dažādos mācību algoritmus, ko var izmantot mūsu datiem, var redzēt nākamajā attēlā. Atkarībā no datu kopas rakstura un eksperimenta prasībām var eksperimentēt ar dažādiem algoritmiem.
Piemēram, ja strādājat ar neiezīmētiem datiem un ir jāatrod līdzības starp dažādiem datu kopas datu punktiem, dažādu pieejamo opciju klasterizācijas algoritms var palīdzēt labāk izprast datu punktus. Tas galu galā palīdz marķēt un klasificēt datu punktus, lai eksperimentu varētu veidot, izmantojot visaptverošākus uzraudzītus mācību algoritmus.
Secinājums
The Ķīlis datu analīzes platforma ir labs resurss gan pētniecības, gan izglītības nolūkos. Tas ir ērti lietojams grafiskais lietotāja interfeiss, kas palīdz lietotājiem labāk izprast datu prasības, kā arī sniedz loģiskas atsauces uz noderīgām metodēm un algoritmiem, kas vēl vairāk palīdz lietotājiem viņu darbplūsmās. Plašs dažādu algoritmu klāsts, kas ietilpst dažādās kategorijās un algoritmiskās metodes, ļauj lietotājiem eksperimentēt ar daudziem loģiskiem virzieniem un salīdzināt šos rezultātus, lai varētu sasniegt optimālāko risinājumu jebkurai problēmai.
Keel bezkoda vilkšanas un nomešanas pieeja datu ieguvei palīdz pat iesācējiem bez piepūles strādāt ar visaptverošiem skaitļošanas inteliģences modeļiem. Tas sniedz ieskatu sarežģītās datu kopās un rezultātā iegūst noderīgus secinājumus, kas palīdz atrisināt reālās pasaules problēmas.