Daudzkārtēja apstrāde ir salīdzināma ar vairāku pavedienu apstrādi. Tomēr tas atšķiras ar to, ka mēs varam izpildīt tikai vienu pavedienu brīdī, pateicoties GIL, kas tiek izmantots pavedienu veidošanai. Daudzapstrāde ir process, kurā secīgi tiek veiktas darbības vairākos CPU kodolos. Pavedienus nevar darbināt paralēli. Tomēr daudzapstrāde ļauj mums izveidot procesus un palaist tos vienlaikus dažādos CPU kodolos. Cilpa, piemēram, for-cilpa, ir viena no visbiežāk izmantotajām skriptu valodām. Atkārtojiet to pašu darbu, izmantojot dažādus datus, līdz tiek sasniegts kāds kritērijs, piemēram, iepriekš noteikts atkārtojumu skaits. Cilpa izpilda katru iterāciju pa vienam.
1. piemērs. For-loop izmantošana Python daudzapstrādes modulī
Šajā piemērā mēs izmantojam for-loop un Python vairāku apstrādes moduļu klases procesu. Mēs sākam ar ļoti vienkāršu piemēru, lai jūs varētu ātri saprast, kā darbojas Python daudzapstrādes for-cilpa. Izmantojot interfeisu, kas ir salīdzināms ar vītņu moduli, daudzapstrāde iesaiņo procesu izveidi.
Izmantojot apakšprocesus, nevis pavedienus, vairāku apstrādes pakotne nodrošina gan lokālu, gan attālu vienlaicību, tādējādi izvairoties no globālās tulkotāja bloķēšanas. Izmantojiet for-cilpu, kas var būt virknes objekts vai virkne, lai nepārtraukti atkārtotu secību. Tas darbojas mazāk kā atslēgvārds, kas redzams citās programmēšanas valodās, un vairāk kā iteratora metode, kas atrodama citās programmēšanas valodās. Uzsākot jaunu vairāku apstrādi, varat palaist for-cilpu, kas vienlaikus izpilda procedūru.
Sāksim ar koda ieviešanu koda izpildei, izmantojot rīku “spyder”. Mēs uzskatām, ka “spyder” ir arī labākais Python palaišanai. Mēs importējam vairāku apstrādes moduļa procesu, kurā darbojas kods. Daudzapstrāde Python koncepcijā, ko sauc par “procesa klasi”, izveido jaunu Python procesu, dod tam metodi koda izpildei un sniedz vecāku lietojumprogrammai veidu, kā pārvaldīt izpildi. Process klase satur start() un join() procedūras, kuras abas ir ļoti svarīgas.
Tālāk mēs definējam lietotāja definētu funkciju, ko sauc par “func”. Tā kā tā ir lietotāja definēta funkcija, mēs tai piešķiram mūsu izvēlētu nosaukumu. Šīs funkcijas pamattekstā mēs nododam mainīgo “subject” kā argumentu un vērtību “matemātika”. Tālāk mēs izsaucam funkciju “print()”, nododot paziņojumu “Vispārējā subjekta nosaukums ir”, kā arī tā argumentu “subject”, kas satur vērtību. Pēc tam nākamajā darbībā mēs izmantojam “if name== _main_”, kas neļauj palaist kodu, kad fails tiek importēts kā modulis, un ļauj to darīt tikai tad, ja saturs tiek izpildīts kā skripts.
Nosacījumu sadaļu, ar kuru sākat, vairumā gadījumu var uzskatīt par vietu, kur nodrošināt saturu, kas jāizpilda tikai tad, kad fails tiek palaists kā skripts. Pēc tam mēs izmantojam argumenta priekšmetu un saglabājam tajā dažas vērtības, kas ir “zinātne”, “angļu valoda” un “dators”. Pēc tam procesam nākamajā darbībā tiek piešķirts nosaukums “process1[]”. Pēc tam mēs izmantojam “process(target=func)”, lai izsauktu funkciju procesā. Mērķis tiek izmantots, lai izsauktu funkciju, un mēs saglabājam šo procesu mainīgajā “P”.
Tālāk mēs izmantojam “process1”, lai izsauktu funkciju “append()”, kas pievieno vienumu saraksta beigām, kas mums ir funkcijā “func”. Tā kā process tiek saglabāts mainīgajā “P”, mēs nododam “P” šai funkcijai kā argumentu. Visbeidzot, lai sāktu procesu, mēs izmantojam funkciju “start()” ar “P”. Pēc tam mēs palaižam metodi vēlreiz, vienlaikus sniedzot argumentu “subject” un priekšmetā lietojam “for”. Pēc tam, vēlreiz izmantojot metodi “process1” un “add()”, mēs sākam procesu. Pēc tam process tiek palaists un izvade tiek atgriezta. Pēc tam procedūra tiek lūgta beigties, izmantojot paņēmienu “join()”. Procesi, kas neizsauc procedūru “join()”, netiks aizvērti. Viens no būtiskiem aspektiem ir tas, ka ir jāizmanto atslēgvārda parametrs “args”, ja procesa laikā vēlaties sniegt argumentus.
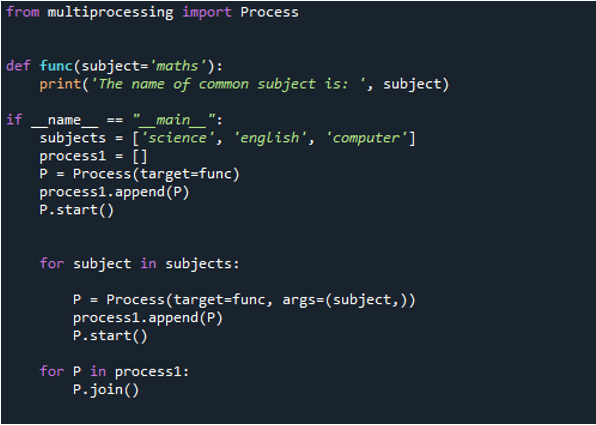
Tagad izvadā var redzēt, ka paziņojums tiek parādīts vispirms, nododot vērtību priekšmetam “matemātika”, kuru mēs nododam funkcijai “func”, jo vispirms mēs to izsaucam, izmantojot funkciju “process”. Pēc tam mēs izmantojam komandu “append()”, lai iegūtu vērtības, kas jau bija sarakstā, kas tiek pievienots beigās. Pēc tam tika prezentēti “zinātne”, “dators” un “angļu valoda”. Bet, kā redzat, vērtības nav pareizajā secībā. Tas ir tāpēc, ka viņi to dara tik ātri, kad procedūra ir pabeigta, un ziņo par savu ziņojumu.
piemērs
Šajā piemērā daudzapstrādes cilpas uzdevums tiek izpildīts secīgi, pirms tiek pārveidots par paralēlu cilpas uzdevumu. Varat pārslēgt secības, piemēram, kolekciju vai virkni, to rašanās secībā, izmantojot for-cilpas.
Tagad sāksim ieviest kodu. Pirmkārt, mēs importējam “miegu” no laika moduļa. Izmantojot “sleep()” procedūru laika modulī, jūs varat apturēt izsaucošā pavediena izpildi tik ilgi, cik vēlaties. Pēc tam mēs izmantojam “random” no nejaušā moduļa, definējam funkciju ar nosaukumu “func” un nododam atslēgvārdu “argu”. Pēc tam mēs izveidojam nejaušu vērtību, izmantojot “val”, un iestatām to uz “random”. Pēc tam mēs uz kādu laiku bloķējam, izmantojot metodi “sleep()” un nododam “val” kā parametru. Pēc tam, lai pārsūtītu ziņojumu, mēs palaižam metodi “print()”, kā parametru nododot vārdus “ready” un atslēgvārdu “arg”, kā arī “created” un nododam vērtību, izmantojot “val”.
Visbeidzot, mēs izmantojam “flush” un iestatām to uz “True”. Lietotājs var izlemt, vai buferēt izvadi, izmantojot Python drukas funkcijas skalošanas opciju. Šī parametra noklusējuma vērtība False norāda, ka izvade netiks buferizēta. Izvade tiek parādīta kā rindas, kas seko viena otrai, ja iestatāt to uz True. Pēc tam mēs izmantojam “ja nosaukums== galvenais”, lai nodrošinātu ieejas punktus. Tālāk mēs izpildām darbu secīgi. Šeit mēs iestatām diapazonu uz “10”, kas nozīmē, ka cilpa beidzas pēc 10 iterācijām. Pēc tam mēs izsaucam funkciju “print()”, nododam tai ievades paziņojumu “gatavs” un izmantojam opciju “flush=True”.
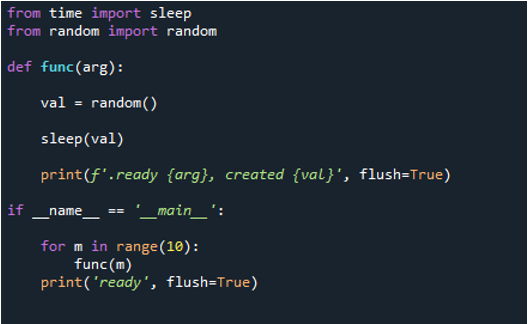
Tagad varat redzēt, ka, izpildot kodu, cilpa liek funkcijai darboties “10” reizes. Tas atkārtojas 10 reizes, sākot no nulles indeksa un beidzot ar indeksu deviņi. Katrs ziņojums satur uzdevuma numuru, kas ir funkcijas numurs, ko mēs nododam kā “arg” un izveides numuru.
Šī secīgā cilpa tagad tiek pārveidota par daudzapstrādes paralēlu for-cilpu. Mēs izmantojam vienu un to pašu kodu, taču vairākkārtējai apstrādei mēs izmantojam dažas papildu bibliotēkas un funkcijas. Tāpēc mums ir jāimportē process no daudzapstrādes, tāpat kā mēs paskaidrojām iepriekš. Pēc tam mēs izveidojam funkciju ar nosaukumu “func” un nododam atslēgvārdu “arg”, pirms izmantojat “val=random”, lai iegūtu nejaušu skaitli.
Pēc tam pēc metodes “print()” izsaukšanas, lai parādītu ziņojumu, un parametra “val” došanas, lai aizkavētu nelielu periodu, mēs izmantojam funkciju “if name= main”, lai nodrošinātu ieejas punktus. Pēc tam mēs izveidojam procesu un izsaucam funkciju procesā, izmantojot “process”, un nododam “target=func”. Pēc tam mēs izlaižam “func”, “arg”, nododam vērtību “m” un nododam diapazonu “10”, kas nozīmē, ka cilpa pārtrauc funkciju pēc “10” iterācijām. Pēc tam mēs sākam procesu, izmantojot “start()” metodi ar “process”. Pēc tam mēs izsaucam metodi “join()”, lai gaidītu procesa izpildi un pēc tam pabeigtu visu procesu.
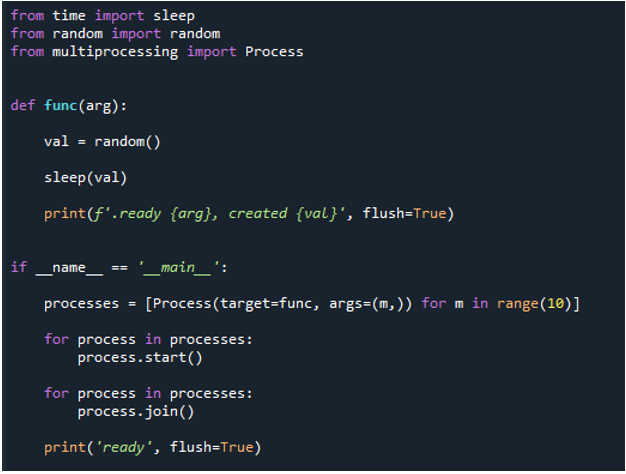
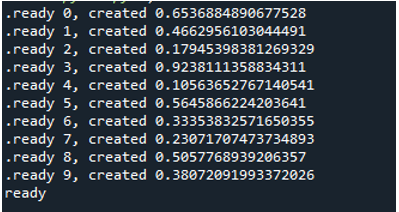
Tāpēc, izpildot kodu, funkcijas izsauc galveno procesu un sāk to izpildi. Tomēr tie tiek veikti, līdz visi uzdevumi ir izpildīti. Mēs to varam redzēt, jo katrs uzdevums tiek veikts vienlaikus. Tas ziņo savu ziņojumu, tiklīdz tas ir pabeigts. Tas nozīmē, ka, lai gan ziņojumi nav kārtībā, cilpa beidzas pēc visu “10” iterāciju pabeigšanas.
Secinājums
Šajā rakstā mēs apskatījām Python daudzapstrādes for-cilpu. Mēs piedāvājām arī divas ilustrācijas. Pirmajā ilustrācijā parādīts, kā Python cilpas daudzapstrādes bibliotēkā izmantot cilpu. Otrajā ilustrācijā ir parādīts, kā secīgu for-cilpu mainīt par paralēlu daudzapstrādes cilpu. Pirms Python daudzapstrādes skripta izveides mums ir jāimportē vairāku apstrādes modulis.