Pandas Set_Option metode
Šodien mēs apskatīsim, kā izmantot funkciju “pd.set_option()”, lai parādītu visas Pandas datu rāmja slejas, parādot to savā Spyder rīkā. Lai izmantotu “pd.set_option()”, mēs izpildām norādīto sintakse:

Sāksim apgūt jēdzienu ar Python programmas praktiskas ieviešanas palīdzību.
Piemērs: Pandas Set_Option metodes izmantošana, lai parādītu visas kolonnas
Šī demonstrācija ir ceļvedis, lai parādītu visas kolonnas DataFrame, izmantojot Pandas “set_option()”. Mēs precizēsim katru šīs Python metodes ieviešanas darbību.
Pirmā prasība, lai praktiski ieviestu Python skriptu, ir atrast labāko rīku, kurā jūs izpildāt savu programmu. Rīks, ko izmantojām ilustrācijai, ir rīks “Spyder”. Mēs palaidām rīku un sākām strādāt pie Python skripta.
Sākot ar kodu, mums sākotnēji ir jāimportē šajā programmā nepieciešamās priekšnosacījumu bibliotēkas. Pirmā bibliotēka, ko ielādējām savā Python failā, ir Pandas bibliotēka, jo funkcijas, kuras mēs šeit izmantojam, nodrošina Pandas. Mēs nosaucām šo bibliotēku kā “pd”. Otrā bibliotēka, kuru ielādējām, ir NumPy bibliotēka. NumPy (Numerical Python) ir skaitliskās skaitļošanas pakotne, kas izstrādāta, izmantojot Python programmēšanu. Koda sadaļa Importēt NumPy liek Python integrēt NumPy moduli jūsu pašreizējā Python failā. Pēc tam skripta daļa “as np” uzdod Python piešķirt NumPy saīsinājumu “np”. Tas ļauj izmantot NumPy metodes, ievadot “np.function_name”, nevis NumPy.
Tagad mēs sākam ar galveno kodu. Mūsu programmas galvenā un pamatvajadzība ir Pandas DataFrame. Tātad, mēs parādām visas tajā esošās kolonnas. Tagad tas ir pilnībā atkarīgs no jums, vai vēlaties izveidot DataFrame ar noteiktām vērtībām vai arī jums ir nepieciešams importēt CSV failu. Šim gadījumam mēs izvēlējāmies DataFrame izveidi ar NaN vērtībām. Mēs izmantojām metodi “pd.DataFrame()”, lai izveidotu DataFrame. Šeit mēs nodrošinājām divus parametrus - 'indekss' un 'kolonnas'. Arguments “indekss” attiecas uz rindām, kas nozīmē, ka mēs iestatām rindas DataFrame.
Mēs piešķīrām parametru “index” un funkciju NumPy “np.arange() ar vērtību skaitu “6”. Tas ģenerē sešas rindas DataFrame. Tas aizpilda visus ierakstus ar NaN vērtībām, jo mēs tam neesam nodrošinājuši nekādu vērtību. Arguments “kolonnas”, kā norāda nosaukums, tiek izmantots, lai iestatītu DataFrame kolonnas. Tai ir arī piešķirta funkcija “np.arange()” ar vērtību “25” kolonnām. Tādējādi tas izveido 25 kolonnas DataFrame.
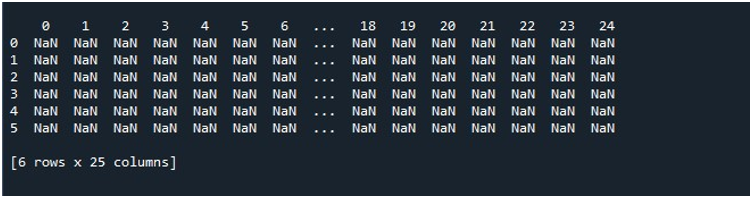
Līdz ar to, izsaucot funkciju “pd.DataFrame()”, mums ir DataFrame ar 25 kolonnām un 6 rindām, kas aizpildītas ar nulles vērtībām. Lai saglabātu šo DataFrame, mums ir jāizveido DataFrame objekts, kurā tiek saglabāts tā saturs. Tāpēc mēs izveidojām DataFrame objektu “random” un piešķīrām tam rezultātu, ko iegūstam no metodes “pd.DataFrame()”. Tagad jūs noteikti vēlaties redzēt, kā tiek ģenerēts DataFrame. Python nodrošina mums metodi, kā skatīt izvadi ekrānā, kas ir funkcija “print ()”. Mēs izmantojām šo metodi, kā parametru nododot DataFrame objektu “random”.
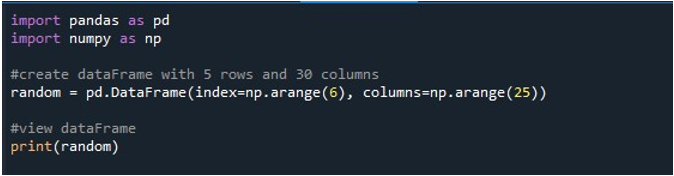
Kad mēs izpildām šo koda fragmentu, mēs saņemam savu DataFrame ar NaN vērtībām, kas tiek parādītas terminālī. Šeit mēs varam novērot, ka ir redzamas dažas no pirmajām kolonnām un tikai dažas no beigām. Visas starp kolonnas ir saīsinātas. Pēc noklusējuma tas slēpj dažas rindas un kolonnas, lai neradītu lietotāja neapmierinātību, parādot milzīgas datu kopas.
Varat pat pārbaudīt kopējo kolonnu skaitu DataFrame, izmantojot Pandas funkciju “len()”. Ierakstiet funkciju “len()” sava “Spyder” rīka konsolē. Ierakstiet DataFrame nosaukumu starp iekavām ar rekvizītu “.columns”. Tas atgriež mums kopējo kolonnu garumu jūsu DataFrame.

Tas atgriež mūsu DataFrame garumu, kas ir 25.
Tagad nākamais un galvenais uzdevums ir mainīt noklusējuma opciju, lai parādītu izvadi. Var būt apstākļi, kad terminālī vēlaties skatīt visu DataFrame. Noklusējuma vērtību dēļ daudzi ieraksti tiek saīsināti, kas rada lietotāja vilšanos. Šeit jūs uzzināsit, kā pārvarēt šo problēmu. Pandas nodrošina mums funkciju “pd.set_option()”, lai mainītu noklusējuma displeja iestatījumus. Uzreiz pēc DataFrame parādīšanas konsolē mēs izsaucam metodi “pd.set_option()”. Mēs norādām parametru starp šīs funkcijas iekavām, kas mums jāizmanto, lai parādītu visas DataFrame kolonnas.
Šeit mēs izmantojām “display.max_columns”, lai parādītu maksimālo kolonnu skaitu mūsu DataFrame. Mēs varam arī definēt šī parametra vērtību, t.i., maksimālās kolonnas, kuras vēlaties parādīt. No otras puses, mēs iestatījām “display.max_columns” uz “None”, kas parāda visas kolonnas no DataFrame ar maksimālo garumu. Visbeidzot, mēs izmantojām funkciju “print ()”, lai parādītu iegūto DataFrame ar visām terminālī redzamajām kolonnām.
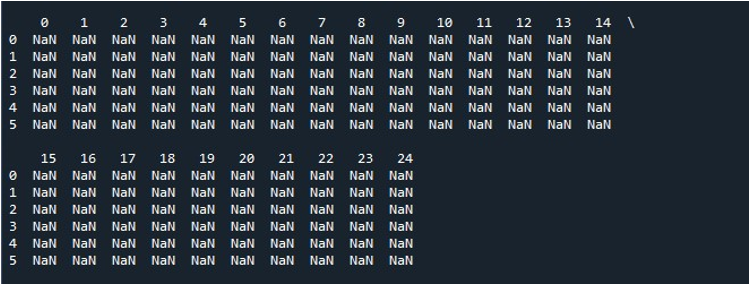
Kad mēs noklikšķinām uz opcijas “Palaist failu” rīkā “Spyder”, mēs varam skatīt izstādīto DataFrame. Šajā DataFrame ir sešas rindas, un tajā ir 25 kolonnu. Nav saīsinātu kolonnu, jo tagad ir iespējota funkcija “pd.set_option()” ar maksimālo kolonnas garumu.
Mēs pat varam atiestatīt displeja opciju, jo, tiklīdz tiek iestatīts maksimālais displeja garums, tas turpina rādīt DataFrames ar visām kolonnām konkrētajā Python failā. Šim nolūkam mēs izmantojam Pandas “pd.reset_option()”. Mēs izsaucam šo funkciju un kā šīs funkcijas parametru nodrošinām “display.max_columns”.

Tādējādi mēs iegūstam sākotnējos displeja iestatījumus nodrošinātajam DataFrame.
Secinājums
Lai skatītu visu termināļa izvadi ar milzīgu datu kopu, dažkārt mēs nonākam grūtībās, kad rīka noklusējuma iestatījumi ir pretrunā ar lietotāja vajadzībām. Lai atrisinātu šo neveiksmi, Pandas mums piedāvā metodi “pd.set_option()”. Šajā mācību rokasgrāmatā mēs jūs iepazīstinājām ar šo metodi un nepieciešamību to izmantot. Tēmu demonstrējām ar praktiski sastādītiem un izpildītiem Python paraugkodiem. Mēs atveidojām 'Spyder' veiktās ilustrācijas rezultātus. Mēs paskaidrojām, kā konsolē parādīt visas DataFrame kolonnas, mainot noklusējuma iestatījumus, kā arī atiestatot visus iestatījumus uz sākotnējiem. Pievēršot uzmanību moduļa praktiskajai ieviešanai, varat to izmantot ikreiz, kad rodas šādas problēmas.