Kā MongoDB darbojas grupu apkopošana?
Operators $group ir jāizmanto, lai grupētu ievades dokumentus atbilstoši norādītajai _id izteiksmei. Pēc tam tai jāatgriež viens dokuments ar kopējām vērtībām katrai atsevišķai grupai. Lai sāktu ar ieviešanu, MongoDB esam izveidojuši kolekciju “Grāmatas”. Pēc kolekcijas “Grāmatas” izveidošanas esam ievietojuši dokumentus, kas saistīti ar dažādiem laukiem. Dokumenti tiek ievietoti kolekcijā, izmantojot metodi insertMany(), kā tālāk ir parādīts izpildāmais vaicājums.
>db.Books.insertMany([{
_id:1,
nosaukums: 'Anna Kareņina',
cena: 290,
gads: 1879.
order_status: 'Ir noliktavā',
autors: {
'vārds': 'Ļevs Tolstojs'
}
},
{
_id:2,
nosaukums: 'Nogalināt mockingbird',
cena: 500,
gads: 1960,
order_status: 'nav noliktavā',
autors: {
'vārds': 'Hārpers Lī'
}
},
{
_id:3,
nosaukums: 'Neredzamais cilvēks',
cena: 312,
gads: 1953.
order_status: 'Ir noliktavā',
autors: {
'vārds': 'Ralfs Elisons'
}
},
{
_id:4,
nosaukums: 'Mīļotais',
cena: 370,
gads: 1873,
order_status: 'out_of_stock',
autors: {
'vārds': 'Tonijs Morisons'
}
},
{
_id:5,
nosaukums: 'Things Fall Apart',
cena: 200,
gads: 1958,
order_status: 'Ir noliktavā',
autors: {
'nosaukums': 'Chinua Achebe'
}
},
{
_id:6,
nosaukums: 'The Color Purple',
cena: 510,
gads: 1982,
order_status: 'nav noliktavā',
autors: {
'vārds':'Alise Vokere'
}
}
])
Dokumenti tiek veiksmīgi saglabāti kolekcijā “Grāmatas”, bez kļūdām, jo izvade tiek atzīta par “patiesu”. Tagad mēs izmantosim šos krājuma “Grāmatas” dokumentus, lai veiktu “$group” agregāciju.

1. piemērs: $group agregācijas izmantošana
Šeit ir parādīta vienkārša $group agregācijas izmantošana. Apkopotais vaicājums vispirms ievada operatoru “$group”, pēc tam operators “$group” tālāk izmanto izteiksmes, lai ģenerētu grupētos dokumentus.
>db.Books.aggregate([
{ $group:{ _id:'$autora.nosaukums'} }
])
Iepriekš minētais operatora $group vaicājums ir norādīts ar lauku “_id”, lai aprēķinātu visu ievades dokumentu kopējās vērtības. Pēc tam lauks “_id” tiek piešķirts ar “$author.name”, kas veido citu grupu laukā “_id”. Tiks atgrieztas atsevišķas $author.name vērtības, jo mēs neaprēķinām nekādas uzkrātās vērtības. $group apkopojuma vaicājuma izpildei ir šāda izvade. Laukā _id ir autora.nosaukumi vērtības.

2. piemērs: $group agregācijas izmantošana ar $push akumulatoru
$group agregācijas piemērā tiek izmantots jebkurš akumulators, kas jau minēts iepriekš. Bet mēs varam izmantot akumulatorus $ grupas apkopošanā. Akumulatoru operatori ir tie, kas tiek izmantoti ievades dokumenta laukos, kas nav tie, kas ir “grupēti” zem “_id”. Pieņemsim, ka mēs vēlamies iespiest izteiksmes laukus masīvā, tad “$push” akumulators tiek izsaukts operatorā “$group”. Šis piemērs palīdzēs skaidrāk izprast “$grupas” akumulatoru “$push”.
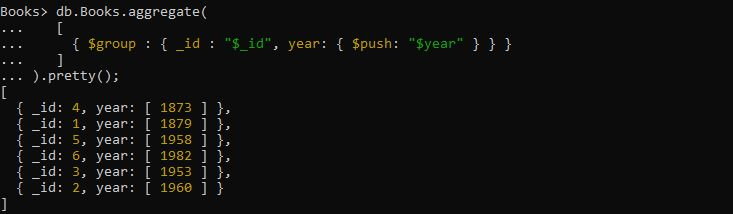
>db.Books.aggregate([
{ $grupa : { _id : '$_id', gads: { $push: '$year' } } }
]
).pretty();
Šeit mēs vēlamies grupēt masīvā norādīto grāmatu izdošanas gada datumu. Lai to paveiktu, ir jāizmanto iepriekš minētais vaicājums. Apkopošanas vaicājums tiek nodrošināts ar izteiksmi, kur operators “$group” izmanto lauka izteiksmi “_id” un lauka izteiksmi “year”, lai iegūtu grupas gadu, izmantojot $push akumulatoru. No šī konkrētā vaicājuma izgūtā izvade izveido gada lauku masīvu un tajā saglabā atgriezto grupēto dokumentu.
3. piemērs: $group agregācijas izmantošana ar “$min” akumulatoru
Tālāk mums ir akumulators “$min”, kas tiek izmantots $group apkopošanā, lai iegūtu minimālo atbilstības vērtību no katra kolekcijas dokumenta. $min akumulatora vaicājuma izteiksme ir norādīta zemāk.
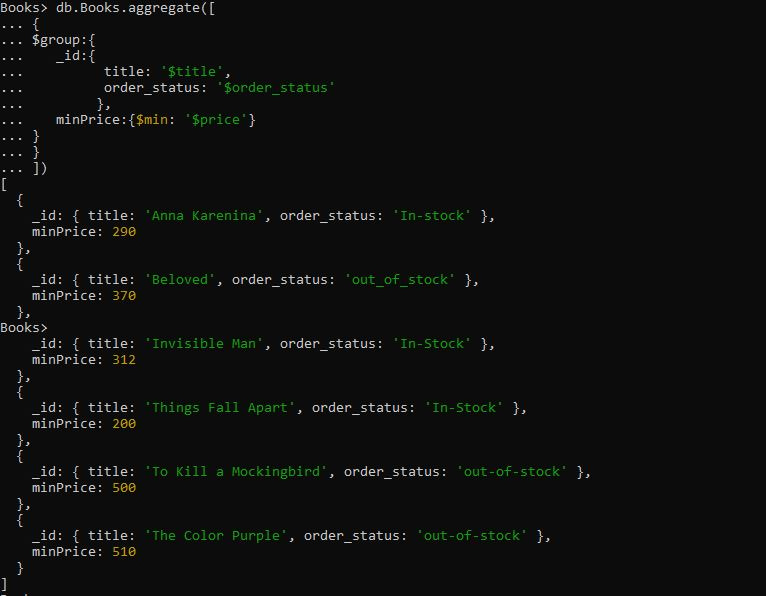
>db.Books.aggregate([{
$group:{
_id:{
virsraksts: '$title',
order_status: '$order_status'
},
minPrice:{$min: '$price'}
}
}
])
Vaicājumam ir apkopošanas izteiksme “$group”, kurā esam sagrupējuši dokumentu laukiem “title” un “order_status”. Pēc tam mēs nodrošinājām $min akumulatoru, kas grupēja dokumentus, iegūstot minimālās cenas vērtības no negrupētajiem laukiem. Kad mēs izpildām šo $min akumulatora vaicājumu zemāk, tas atgriež grupētos dokumentus pēc nosaukuma un order_status secībā. Minimālā cena tiek rādīta vispirms, un dokumenta augstākā cena tiek ievietota pēdējā.
4. piemērs: izmantojiet $group agregāciju ar $sum akumulatoru
Lai iegūtu visu skaitlisko lauku summu, izmantojot operatoru $group, tiek izvietota $sum akumulatora darbība. Šajā akumulatorā tiek ņemtas vērā kolekcijās esošās vērtības, kas nav skaitliskas. Turklāt mēs šeit izmantojam $match apkopojumu ar $group apkopojumu. $match agregācija pieņem vaicājuma nosacījumus, kas ir doti dokumentā, un nodod atbilstošo dokumentu $group apkopojumam, kas pēc tam atgriež dokumenta summu katrai grupai. $summas akumulatoram vaicājums ir parādīts zemāk.
>db.Books.aggregate([{ $match:{ order_status:'Ir noliktavā'}},
{ $group:{ _id:'$autora.nosaukums', totalBooks: { $sum:1 } }
}])
Iepriekš minētais apkopošanas vaicājums sākas ar operatoru $match, kas atbilst visiem “order_status”, kura statuss ir “Ir noliktavā”, un tiek nodots grupai $ kā ievade. Pēc tam operatoram $group ir izteiksme $sum akumulators, kas izvada visu krājumā esošo grāmatu summu. Ņemiet vērā, ka “$sum:1” pievieno 1 katram dokumentam, kas pieder tai pašai grupai. Šeit tika parādīti tikai divi grupēti dokumenti, kuriem “order_status” ir saistīts ar “In-Stock”.

5. piemērs: izmantojiet $group apkopojumu ar $sort apkopojumu
Operators $group šeit tiek izmantots kopā ar operatoru '$sort', ko izmanto grupēto dokumentu kārtošanai. Nākamajā vaicājumā ir trīs kārtošanas darbības soļi. Pirmais ir $match posms, tad $group posms, un pēdējais ir $sort posms, kas kārto grupēto dokumentu.
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ autora vārds :'$autora.nosaukums'}, totalBooks: { $sum:1} } },
{ $kārtot:{ autora vārds:1}}
])
Šeit mēs esam ieguvuši atbilstošo dokumentu, kura “order_status” nav noliktavā. Pēc tam atbilstošais dokuments tiek ievadīts $group stadijā, kas sagrupēja dokumentu ar lauku “authorName” un “totalBooks”. Izteiksme $group ir saistīta ar $sum akumulatoru ar kopējo grāmatu skaitu, kas nav noliktavā. Pēc tam grupētie dokumenti tiek sakārtoti ar izteiksmi $sort augošā secībā, jo “1” šeit norāda augošā secībā. Sakārtotais grupas dokuments norādītajā secībā tiek iegūts sekojošā izvadā.

6. piemērs: izmantojiet $group apkopojumu atsevišķai vērtībai
Apkopošanas procedūra arī sagrupē dokumentus pēc vienumiem, izmantojot operatoru $group, lai iegūtu atšķirīgās vienumu vērtības. Ļaujiet mums iegūt šī paziņojuma vaicājuma izteiksmi MongoDB.
>db.Books.aggregate( [ { $grupa : { _id : '$nosaukums' } } ] ).pretty();Apkopošanas vaicājums tiek lietots grāmatu kolekcijai, lai iegūtu grupas dokumenta atšķirīgo vērtību. $grupa šeit izmanto izteiksmi _id, kas izvada atšķirīgas vērtības, jo mēs tai esam ievadījuši lauku “nosaukums”. Grupas dokumenta izvade tiek iegūta, palaižot šo vaicājumu, kura virsrakstu nosaukumu grupa atrodas laukā _id.

Secinājums
Rokasgrāmatas mērķis bija notīrīt $group agregācijas operatora jēdzienu dokumenta grupēšanai MongoDB datu bāzē. MongoDB apkopotā pieeja uzlabo grupēšanas parādības. Operatora $group sintakses struktūra ir parādīta ar piemēru programmām. Papildus $group operatoru pamata piemēram mēs esam izmantojuši arī šo operatoru ar dažiem akumulatoriem, piemēram, $push, $min, $sum un tādiem operatoriem kā $match un $sort.