Ātrā kontūra
Šī ziņa parādīs sekojošo:
- Kā pievienot atmiņu OpenAI funkciju aģentam programmā LangChain
- 1. darbība: ietvaru instalēšana
- 2. darbība. Vides iestatīšana
- 3. darbība. Bibliotēku importēšana
- 4. darbība: izveidojiet datu bāzi
- 5. darbība. Datu bāzes augšupielāde
- 6. darbība. Valodas modeļa konfigurēšana
- 7. darbība: atmiņas pievienošana
- 8. darbība. Aģenta inicializācija
- 9. darbība. Aģenta pārbaude
- Secinājums
Kā pievienot atmiņu OpenAI funkciju aģentam LangChain?
OpenAI ir mākslīgā intelekta (AI) organizācija, kas tika izveidota 2015. gadā un sākotnēji bija bezpeļņas organizācija. Kopš 2020. gada Microsoft ir ieguldījusi lielus līdzekļus, jo dabiskās valodas apstrāde (NLP) ar mākslīgo intelektu ir attīstījusies ar tērzēšanas robotiem un valodu modeļiem.
OpenAI aģentu izveide ļauj izstrādātājiem iegūt lasāmākus un precīzākus rezultātus no interneta. Atmiņas pievienošana aģentiem ļauj viņiem labāk izprast tērzēšanas kontekstu un saglabāt atmiņā arī iepriekšējās sarunas. Lai uzzinātu atmiņas pievienošanas procesu OpenAI funkciju aģentam programmā LangChain, vienkārši veiciet tālāk norādītās darbības.
1. darbība: ietvaru instalēšana
Pirmkārt, instalējiet LangChain atkarības no “Langchain-experimental” ietvars, izmantojot šādu kodu:
pip instalēt langchain - eksperimentāls
Instalējiet “google-search-results” modulis, lai iegūtu meklēšanas rezultātus no Google servera:
pip instalējiet google - Meklēt - rezultātus 
Instalējiet arī OpenAI moduli, ko var izmantot, lai izveidotu valodu modeļus programmā LangChain:
pip install openai 
2. darbība: vides iestatīšana
Pēc moduļu iegūšanas iestatiet vides, izmantojot API atslēgas no OpenAI un SerpAPi konti:
imports tuimports getpass
tu. aptuveni [ 'OPENAI_API_KEY' ] = getpass. getpass ( 'OpenAI API atslēga:' )
tu. aptuveni [ 'SERPAPI_API_KEY' ] = getpass. getpass ( 'Serpapi API atslēga:' )
Izpildiet iepriekš minēto kodu, lai ievadītu API atslēgas, lai piekļūtu gan videi, un nospiediet taustiņu Enter, lai apstiprinātu:
3. darbība. Bibliotēku importēšana
Tagad, kad iestatīšana ir pabeigta, izmantojiet no LangChain instalētās atkarības, lai importētu nepieciešamās bibliotēkas atmiņas un aģentu veidošanai:
no langchain. ķēdes imports LLMMathChainno langchain. llms imports OpenAI
#iegūstiet bibliotēku, lai meklētu Google tīklā internetā
no langchain. komunālie pakalpojumi imports SerpAPIWrapper
no langchain. komunālie pakalpojumi imports SQL datu bāze
no langchain_experimental. sql imports SQLDatabaseChain
#iegūstiet bibliotēku rīku izveidei priekš inicializējot aģentu
no langchain. aģenti imports Aģenta veids , Rīks , inicializēt_aģents
no langchain. tērzēšanas_modeļi imports ChatOpenAI
4. darbība: izveidojiet datu bāzi
Lai turpinātu šo rokasgrāmatu, mums ir jāizveido datu bāze un jāizveido savienojums ar aģentu, lai no tās iegūtu atbildes. Lai izveidotu datu bāzi, ir nepieciešams lejupielādēt SQLite, izmantojot šo vadīt un apstipriniet instalēšanu, izmantojot šādu komandu:
sqlite3Palaižot iepriekš minēto komandu programmā Windows terminālis parāda instalēto SQLite versiju (3.43.2):
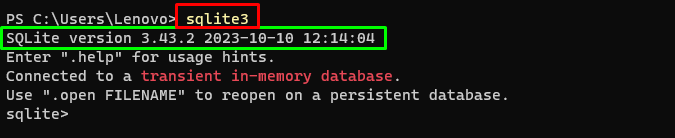
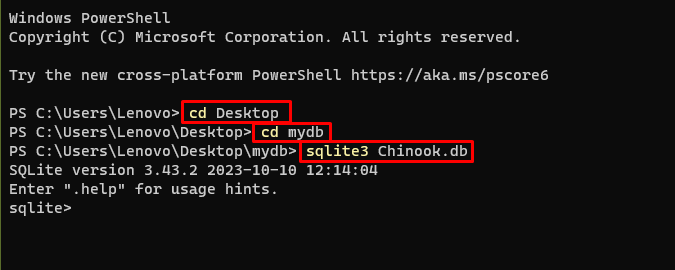
Pēc tam vienkārši dodieties uz datora direktoriju, kurā tiks izveidota un saglabāta datu bāze:
cd darbvirsmacd mydb
sqlite3 Chinook. db
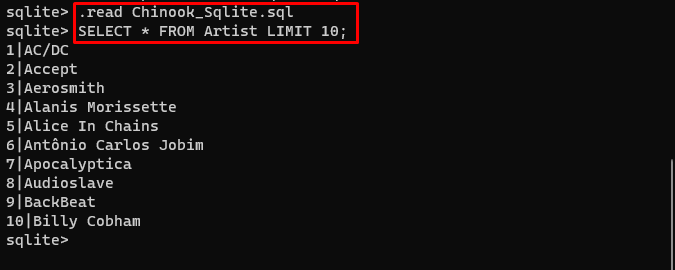
Lietotājs no tā var vienkārši lejupielādēt datubāzes saturu saite direktorijā un izpildiet šo komandu, lai izveidotu datu bāzi:
. lasīt Chinook_Sqlite. sqlATLASĪT * NO izpildītāja LIMIT 10 ;
Datubāze ir veiksmīgi izveidota, un lietotājs tajā var meklēt datus, izmantojot dažādus vaicājumus:
5. darbība. Datu bāzes augšupielāde
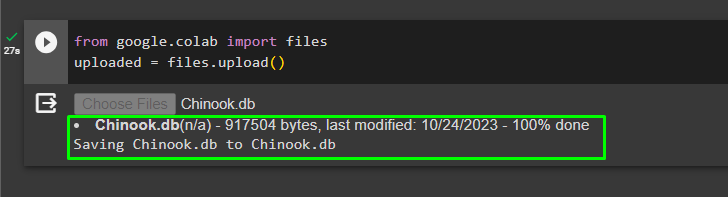
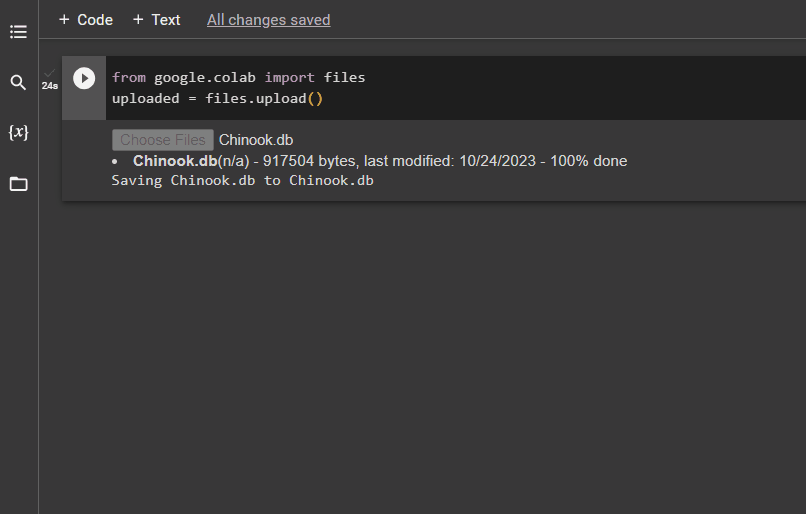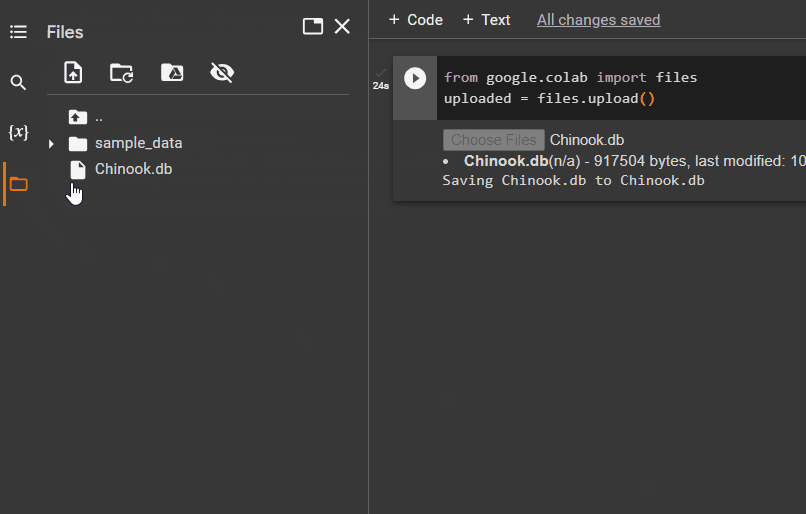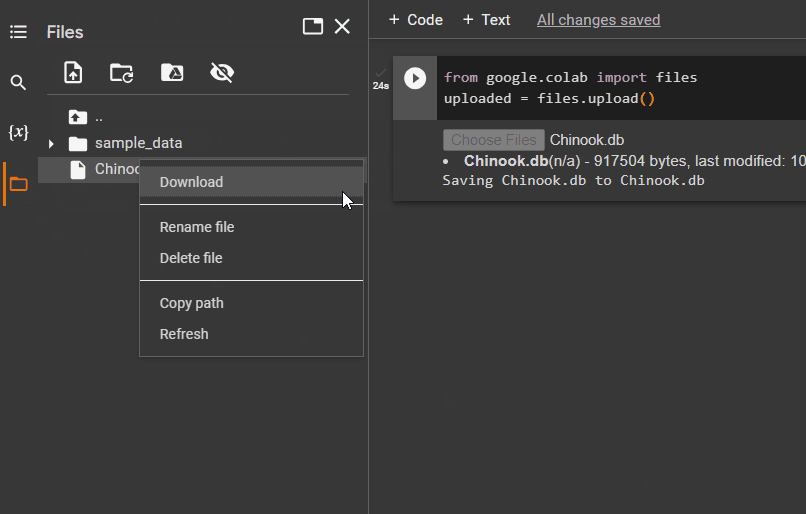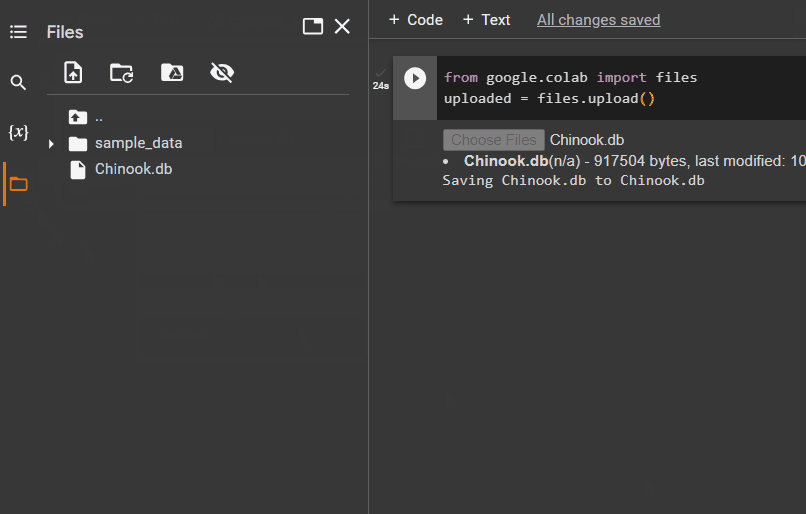
Kad datubāze ir veiksmīgi izveidota, augšupielādējiet “.db” failu Google Colaboratory, izmantojot šādu kodu:
no google. UN CITI imports failusaugšupielādēts = failus. augšupielādēt ( )
Izvēlieties failu no vietējās sistēmas, noklikšķinot uz “Izvēlēties failus” pogu pēc iepriekš minētā koda izpildīšanas:
Kad fails ir augšupielādēts, vienkārši nokopējiet tā faila ceļu, kas tiks izmantots nākamajā darbībā:
6. darbība. Valodas modeļa konfigurēšana
Veidojiet valodas modeli, ķēdes, rīkus un ķēdes, izmantojot šādu kodu:
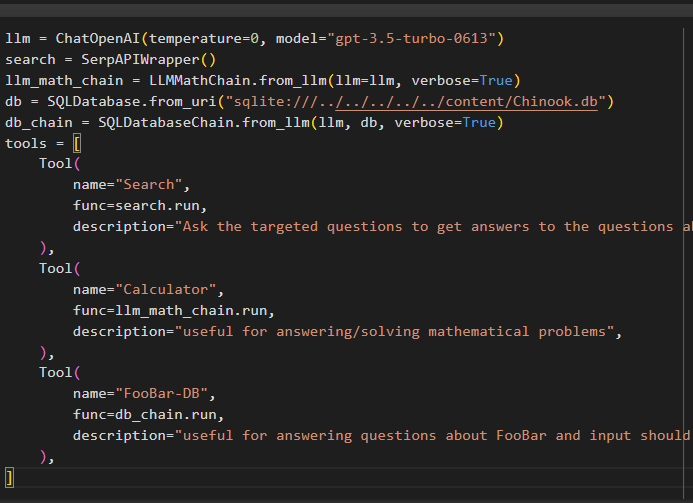
llm = ChatOpenAI ( temperatūra = 0 , modelis = 'gpt-3.5-turbo-0613' )Meklēt = SerpAPIWrapper ( )
llm_math_chain = LLMMathChain. from_llm ( llm = llm , runīgs = Taisnība )
db = SQL datu bāze. no_uri ( 'sqlite:///../../../../../content/Chinook.db' )
db_ķēde = SQLDatabaseChain. from_llm ( llm , db , runīgs = Taisnība )
instrumenti = [
Rīks (
nosaukums = 'Meklēt' ,
func = Meklēt. palaist ,
apraksts = 'Uzdodiet atlasītos jautājumus, lai saņemtu atbildes uz jautājumiem par nesenajiem notikumiem' ,
) ,
Rīks (
nosaukums = 'kalkulators' ,
func = llm_math_chain. palaist ,
apraksts = 'noder, lai atbildētu/risinātu matemātiskos uzdevumus' ,
) ,
Rīks (
nosaukums = 'FooBar-DB' ,
func = db_ķēde. palaist ,
apraksts = 'noderīgs, lai atbildētu uz jautājumiem par FooBar, un ievadei jābūt jautājuma formā, kas satur pilnu kontekstu' ,
) ,
]
- The llm mainīgais satur valodas modeļa konfigurācijas, izmantojot ChatOpenAI() metodi ar modeļa nosaukumu.
- Meklēšana mainīgais satur metodi SerpAPIWrapper(), lai izveidotu aģenta rīkus.
- Veidojiet llm_math_chain lai iegūtu atbildes, kas saistītas ar matemātikas domēnu, izmantojot LLMMathChain() metodi.
- Db mainīgais satur tā faila ceļu, kurā ir datu bāzes saturs. Lietotājam ir jāmaina tikai pēdējā daļa, kas ir “content/Chinook.db” no ceļa, kas saglabā “sqlite:///../../../../../” tas pats.
- Izveidojiet citu ķēdi, lai atbildētu uz vaicājumiem no datu bāzes, izmantojot db_ķēde mainīgs.
- Konfigurējiet tādus rīkus kā Meklēt , kalkulators , un FooBar-DB lai meklētu atbildes, atbildētu uz matemātikas jautājumiem un vaicājumiem attiecīgi no datu bāzes:
7. darbība: atmiņas pievienošana
Pēc OpenAI funkciju konfigurēšanas vienkārši izveidojiet un pievienojiet aģentam atmiņu:
no langchain. uzvednes imports MessagesPlaceholderno langchain. atmiņa imports ConversationBufferMemory
agent_kwargs = {
'extra_prompt_messages' : [ MessagesPlaceholder ( mainīgā_nosaukums = 'atmiņa' ) ] ,
}
atmiņa = ConversationBufferMemory ( atmiņas_atslēga = 'atmiņa' , return_messages = Taisnība )
8. darbība. Aģenta inicializācija
Pēdējais komponents, kas jāizveido un inicializē, ir aģents, kas satur visus komponentus, piemēram, llm , rīks , OPENAI_FUNCTIONS , un citi, kas tiks izmantoti šajā procesā:
aģents = inicializēt_aģents (instrumenti ,
llm ,
aģents = Aģenta veids. OPENAI_FUNCTIONS ,
runīgs = Taisnība ,
agent_kwargs = agent_kwargs ,
atmiņa = atmiņa ,
)
9. darbība. Aģenta pārbaude
Visbeidzot pārbaudiet aģentu, uzsākot tērzēšanu, izmantojot “ Sveiki ” ziņa:
aģents. palaist ( 'Sveiki' ) 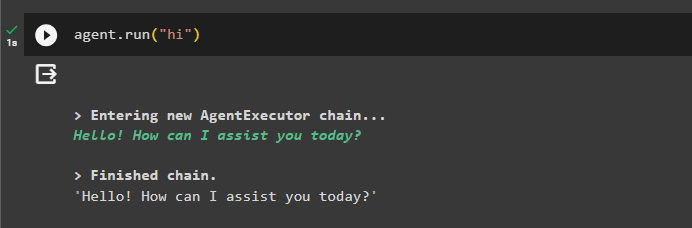
Pievienojiet atmiņai informāciju, palaižot aģentu ar to:
aģents. palaist ( 'Mani sauc Džons Snovs' ) 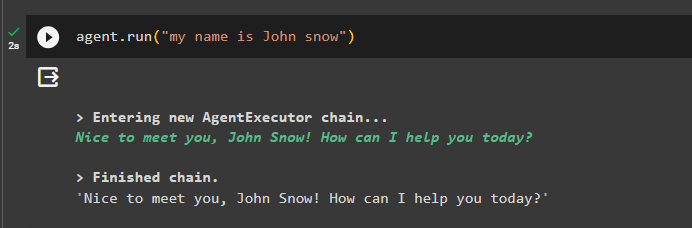
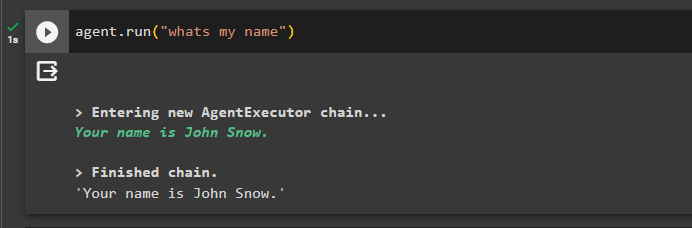
Tagad pārbaudiet atmiņu, uzdodot jautājumu par iepriekšējo tērzēšanu:
aģents. palaist ( 'kāds ir mans vārds' )Aģents ir atbildējis ar nosaukumu, kas iegūts no atmiņas, tāpēc atmiņa veiksmīgi darbojas ar aģentu:
Tas pagaidām ir viss.
Secinājums
Lai pievienotu atmiņu OpenAI funkciju aģentam programmā LangChain, instalējiet moduļus, lai iegūtu bibliotēku importēšanas atkarības. Pēc tam vienkārši izveidojiet datu bāzi un augšupielādējiet to Python piezīmju grāmatiņā, lai to varētu izmantot kopā ar modeli. Konfigurējiet modeli, rīkus, ķēdes un datubāzi pirms to pievienošanas aģentam un inicializējiet to. Pirms atmiņas pārbaudes izveidojiet atmiņu, izmantojot ConversationalBufferMemory() un pievienojiet to aģentam pirms tās testēšanas. Šajā rokasgrāmatā ir aprakstīts, kā pievienot atmiņu OpenAI funkciju aģentam programmā LangChain.