Ātrā kontūra
Šī ziņa parādīs sekojošo:
- Kā pievienot atmiņu gan aģentam, gan tā rīkiem programmā LangChain
- 1. darbība: ietvaru instalēšana
- 2. darbība. Vides iestatīšana
- 3. darbība. Bibliotēku importēšana
- 4. darbība. ReadOnlyMemory pievienošana
- 5. darbība: rīku iestatīšana
- 6. darbība. Aģenta izveide
- 1. metode: ReadOnlyMemory izmantošana
- 2. metode: vienas atmiņas izmantošana gan aģentam, gan rīkiem
- Secinājums
Kā pievienot atmiņu gan aģentam, gan tā rīkiem programmā LangChain?
Atmiņas pievienošana aģentiem un rīkiem ļauj tiem strādāt labāk, izmantojot iespēju izmantot modeļa tērzēšanas vēsturi. Izmantojot atmiņu, aģents var efektīvi izlemt, kuru rīku un kad izvietot. Vēlams izmantot ' Tikai lasāmatmiņa ” gan aģentiem, gan rīkiem, lai viņi to nevarētu modificēt. Lai uzzinātu atmiņas pievienošanas procesu gan aģentiem, gan rīkiem programmā LangChain, veiciet norādītās darbības:
1. darbība: ietvaru instalēšana
Pirmkārt, instalējiet langchain-eksperimentāls moduli, lai iegūtu tā atkarības aģenta valodu modeļu un rīku veidošanai. LangChain eksperimentāls ir modulis, kas iegūst atkarības ēku modeļiem, kurus galvenokārt izmanto eksperimentiem un testiem:
pip instalēt langchain - eksperimentāls
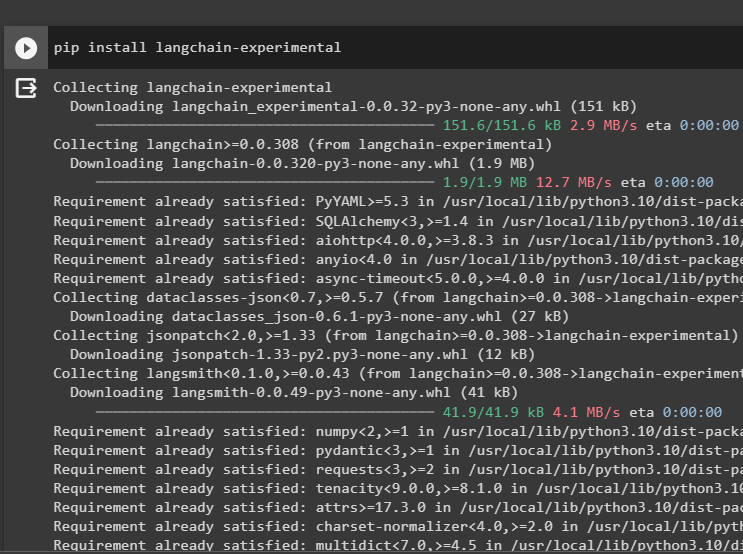
Dabūt google-search-results moduļi ar OpenAI atkarībām, lai iegūtu visatbilstošākās atbildes no interneta:
pip instalēt openai google - Meklēt - rezultātus
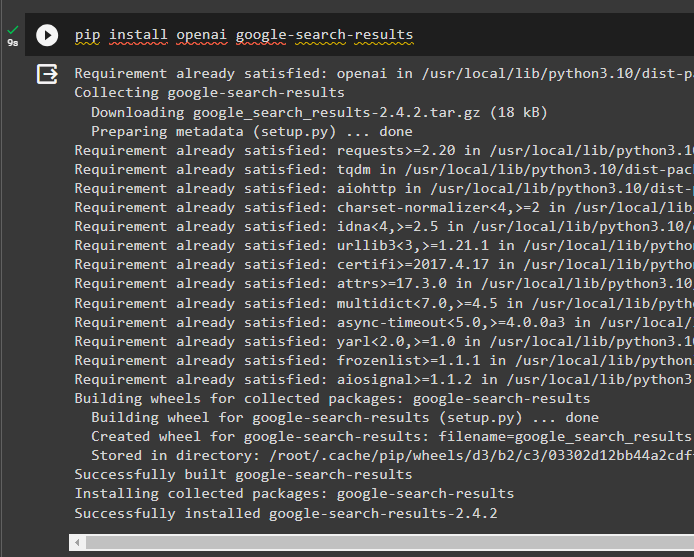
2. darbība: vides iestatīšana
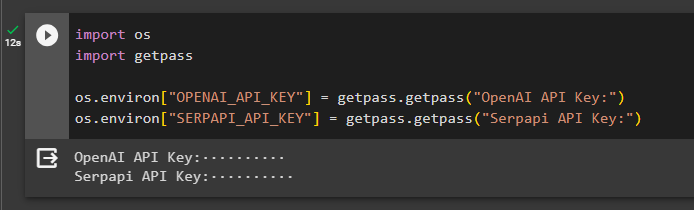
Lai izveidotu modeli, kas saņem atbildes no interneta, ir jāiestata vides, izmantojot OpenAI un SerpAPi atslēgas:
imports tu
imports getpass
tu. aptuveni [ 'OPENAI_API_KEY' ] = getpass. getpass ( 'OpenAI API atslēga:' )
tu. aptuveni [ 'SERPAPI_API_KEY' ] = getpass. getpass ( 'Serpapi API atslēga:' )
3. darbība. Bibliotēku importēšana
Pēc vides iestatīšanas importējiet bibliotēkas, lai izveidotu aģenta rīkus un papildu atmiņu, lai ar tām integrētos. Šis kods izmanto aģentus, atmiņu, llms, ķēdes, uzvednes un utilītas, lai iegūtu nepieciešamās bibliotēkas:
no langchain. aģenti imports ZeroShotAgent , Rīks , Aģents Izpildītājsno langchain. atmiņa imports ConversationBufferMemory , ReadOnlySharedMemory
no langchain. llms imports OpenAI
#iegūstiet bibliotēku priekš ķēdes veidošana, izmantojot LangChain
no langchain. ķēdes imports LLMChain
no langchain. uzvednes imports PromptTemplate
#iegūstiet bibliotēku priekš iegūt informāciju no interneta
no langchain. komunālie pakalpojumi imports SerpAPIWrapper
4. darbība. ReadOnlyMemory pievienošana
Konfigurējiet aģenta veidni, lai sāktu veikt uzdevumus, tiklīdz lietotājs sniedz ievadi. Pēc tam pievienojiet “ConversationBufferMemory()” lai saglabātu modeļa tērzēšanas vēsturi un inicializētu “Tikai lasāmatmiņa” aģentiem un tā instrumentiem:
veidne = '' 'Šī ir saruna starp cilvēku un botu:{chat_history}
#iestatiet struktūru precīza un vienkārša kopsavilkuma iegūšanai
Apkopojiet {input} tērzēšanu:
' ''
pamudināt = PromptTemplate ( ievades_mainīgie = [ 'ievade' , 'tērzēšanas_vēsture' ] , veidne = veidne )
atmiņa = ConversationBufferMemory ( atmiņas_atslēga = 'tērzēšanas_vēsture' )
tikai lasīšanas atmiņa = ReadOnlySharedMemory ( atmiņa = atmiņa )
#kopsavilkuma ķēde, lai integrētu visus komponentus priekš iegūstot sarunas kopsavilkumu
summary_chain = LLMChain (
llm = OpenAI ( ) ,
pamudināt = pamudināt ,
runīgs = Taisnība ,
atmiņa = tikai lasīšanas atmiņa ,
)
5. darbība: rīku iestatīšana
Tagad iestatiet tādus rīkus kā meklēšana un kopsavilkums, lai saņemtu atbildi no interneta kopā ar tērzēšanas kopsavilkumu.
Meklēt = SerpAPIWrapper ( )instrumenti = [
Rīks (
nosaukums = 'Meklēt' ,
func = Meklēt. palaist ,
apraksts = 'pareizas atbildes uz mērķtiecīgiem vaicājumiem par nesenajiem notikumiem' ,
) ,
Rīks (
nosaukums = 'Kopsavilkums' ,
func = summary_chain. palaist ,
apraksts = 'noder, lai apkopotu tērzēšanu, un ievadei šajā rīkā ir jābūt virknei, kas norāda, kurš lasīs šo kopsavilkumu' ,
) ,
]
6. darbība. Aģenta izveide
Konfigurējiet aģentu, tiklīdz rīki ir gatavi veikt nepieciešamos uzdevumus un iegūt atbildes no interneta. ' priedēklis ” mainīgais tiek izpildīts, pirms aģenti piešķir kādu uzdevumu rīkiem un “ piedēklis ” tiek izpildīts pēc tam, kad rīki ir izvilkuši atbildi:
priedēklis = '' 'Sarunājieties ar cilvēku, pēc iespējas labāk atbildot uz šādiem jautājumiem, piekļūstot šādiem rīkiem: ''piedēklis = '' 'Sāciet!'
#struktūra priekš aģents, lai sāktu lietot rīkus atmiņas lietošanas laikā
{ tērzēšanas_vēsture }
Jautājums : { ievade }
{ agent_scratchpad } '' '
prompt = ZeroShotAgent.create_prompt(
#configure uzvedņu veidnes, lai izprastu jautājuma kontekstu
instrumenti,
prefikss=prefikss,
sufikss=sufikss,
input_variables=[' ievade ',' tērzēšanas_vēsture ',' agent_scratchpad '],
)
1. metode: ReadOnlyMemory izmantošana
Kad aģents ir iestatīts rīku izpildei, modelis ar ReadOnlyMemory ir vēlams veids, kā izveidot un izpildīt ķēdes, lai iegūtu atbildes, un process ir šāds:
1. darbība: ķēdes izveidošana
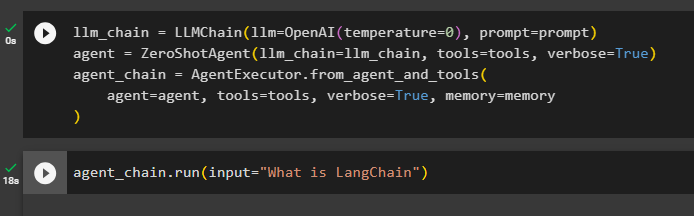
Pirmais solis šajā metodē ir izveidot ķēdi un izpildītāju “ZeroShotAgent()” ar saviem argumentiem. The “LLMChain()” tiek izmantots, lai izveidotu savienojumu starp visām tērzēšanas sarunām valodas modelī, izmantojot llm un uzvednes argumentus. Aģents izmanto llm_chain, tools un verbose kā argumentu un veido agent_chain, lai izpildītu gan aģentus, gan savus rīkus ar atmiņu:
llm_chain = LLMChain ( llm = OpenAI ( temperatūra = 0 ) , pamudināt = pamudināt )aģents = ZeroShotAgent ( llm_chain = llm_chain , instrumenti = instrumenti , runīgs = Taisnība )
aģenta_ķēde = Aģents Izpildītājs. from_agent_and_tools (
aģents = aģents , instrumenti = instrumenti , runīgs = Taisnība , atmiņa = atmiņa
)
2. darbība: ķēdes pārbaude
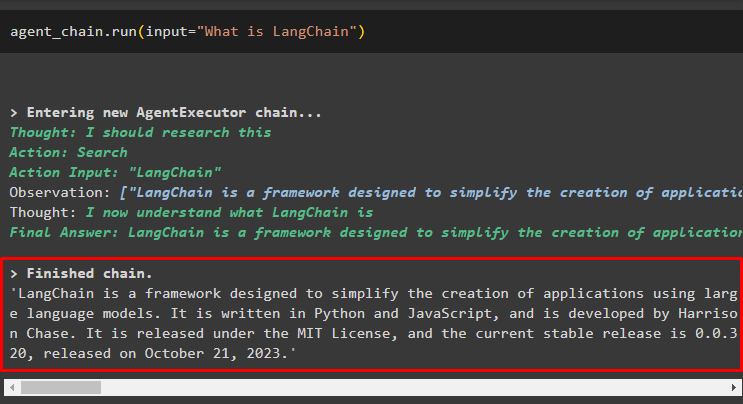
Zvaniet uz aģenta_ķēde izmantojot run() metodi, lai uzdotu jautājumu no interneta:
aģenta_ķēde. palaist ( ievade = 'Kas ir LangChain' )Aģents ir izvilcis atbildi no interneta, izmantojot meklēšanas rīkus:
Lietotājs var uzdot neskaidro papildjautājumu, lai pārbaudītu aģentam pievienoto atmiņu:
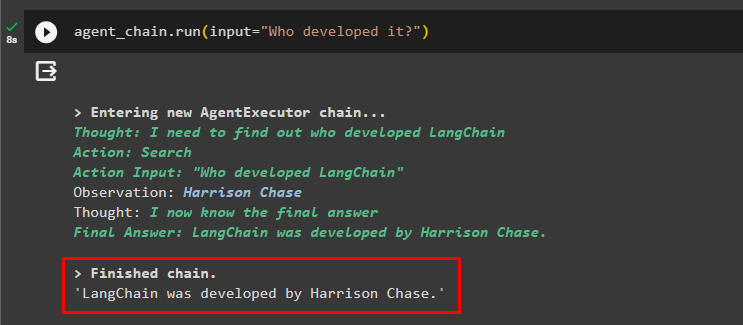
aģenta_ķēde. palaist ( ievade = 'Kas to izstrādāja?' )Aģents ir izmantojis iepriekšējo tērzēšanu, lai izprastu jautājumu kontekstu, un ienesa atbildes, kā parādīts šajā ekrānuzņēmumā:
Aģents izmanto rīku (summary_chain), lai iegūtu visu atbilžu kopsavilkumu, kas iepriekš iegūtas, izmantojot aģenta atmiņu:
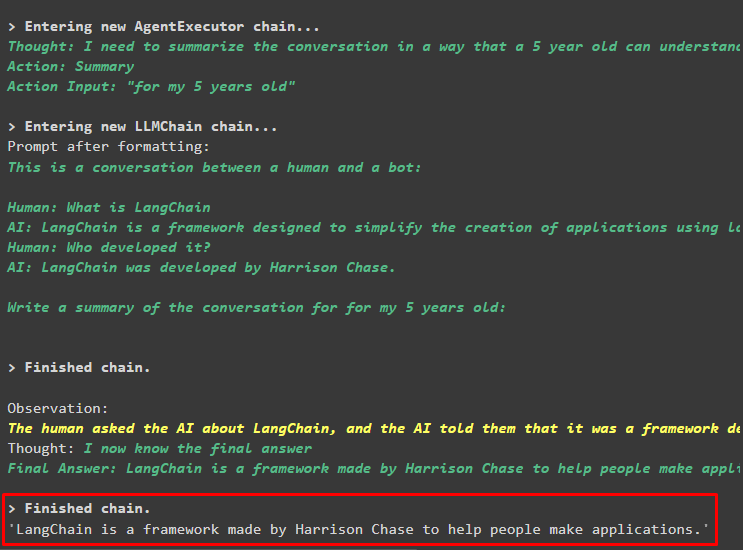
aģenta_ķēde. palaist (ievade = 'Paldies! Apkopojiet sarunu par manu 5 gadu vecumu'
)

Izvade
Iepriekš uzdoto jautājumu kopsavilkums 5 gadus vecam bērnam ir parādīts šādā ekrānuzņēmumā:
3. darbība: atmiņas pārbaude
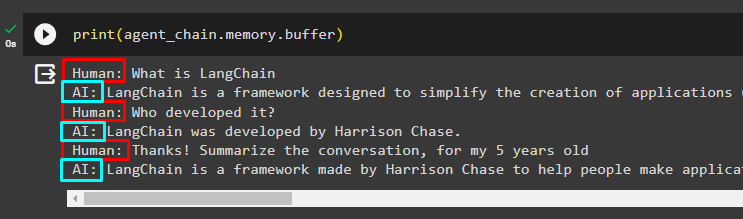
Izdrukājiet buferatmiņu, lai izvilktu tajā saglabātās tērzēšanas sarunas, izmantojot šādu kodu:
drukāt ( aģenta_ķēde. atmiņa . buferis )Tērzēšanas sarunas pareizajā secībā bez jebkādām izmaiņām ir parādītas šajā fragmentā:
2. metode: vienas atmiņas izmantošana gan aģentam, gan rīkiem
Otrā metode, ko platforma neiesaka, ir buferatmiņas izmantošana gan aģentiem, gan rīkiem. Rīki var mainīt atmiņā saglabātās tērzēšanas sarunas, kas var atgriezt nepatiesas izvades lielās sarunās:
1. darbība: ķēdes izveidošana
Izmantojot pilnu kodu no veidnes, lai izveidotu aģentu rīkus un ķēdes ar nelielām izmaiņām, jo šoreiz netiek pievienota ReadOnlyMemory:
veidne = '' 'Šī ir saruna starp cilvēku un botu:{chat_history}
Uzrakstiet {input} sarunas kopsavilkumu:
' ''
#veidojiet tērzēšanas struktūru saskarne izmantojot uzvednes veidni, pievienojot atmiņu ar ķēdi
pamudināt = PromptTemplate ( ievades_mainīgie = [ 'ievade' , 'čatu_vēsture' ] , veidne = veidne )
atmiņa = ConversationBufferMemory ( atmiņas_atslēga = 'tērzēšanas_vēsture' )
summary_chain = LLMChain (
llm = OpenAI ( ) ,
pamudināt = pamudināt ,
runīgs = Taisnība ,
atmiņa = atmiņa ,
)
#veidojiet rīkus ( meklēšana un kopsavilkums ) priekš aģentu konfigurēšana
Meklēt = SerpAPIWrapper ( )
instrumenti = [
Rīks (
nosaukums = 'Meklēt' ,
func = Meklēt. palaist ,
apraksts = 'pareizas atbildes uz mērķtiecīgiem vaicājumiem par nesenajiem notikumiem' ,
) ,
Rīks (
nosaukums = 'Kopsavilkums' ,
func = summary_chain. palaist ,
apraksts = 'noder, lai iegūtu tērzēšanas kopsavilkumu, un šajā rīkā ir jāievada virkne, kas norāda, kurš lasīs šo kopsavilkumu' ,
) ,
]
#izskaidrojiet darbības priekš aģents, lai izmantotu rīkus informācijas iegūšanai priekš tērzēšana
priedēklis = '' 'Sarunājieties ar cilvēku, atbildot uz jautājumiem vislabākajā iespējamajā veidā, piekļūstot šādiem rīkiem: ''
piedēklis = '' 'Sāciet!'
#struktūra priekš aģents, lai sāktu lietot rīkus atmiņas lietošanas laikā
{ tērzēšanas_vēsture }
Jautājums : { ievade }
{ agent_scratchpad } '' '
prompt = ZeroShotAgent.create_prompt(
#configure uzvedņu veidnes, lai izprastu jautājuma kontekstu
instrumenti,
prefikss=prefikss,
sufikss=sufikss,
input_variables=[' ievade ',' tērzēšanas_vēsture ',' agent_scratchpad '],
)
#integrējiet visus komponentus, veidojot aģenta izpildītāju
llm_chain = LLMChain(llm=OpenAI(temperatūra=0), uzvedne=prompt)
aģents = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
aģents=aģents, rīki=rīki, verbose=true, atmiņa=atmiņa
)
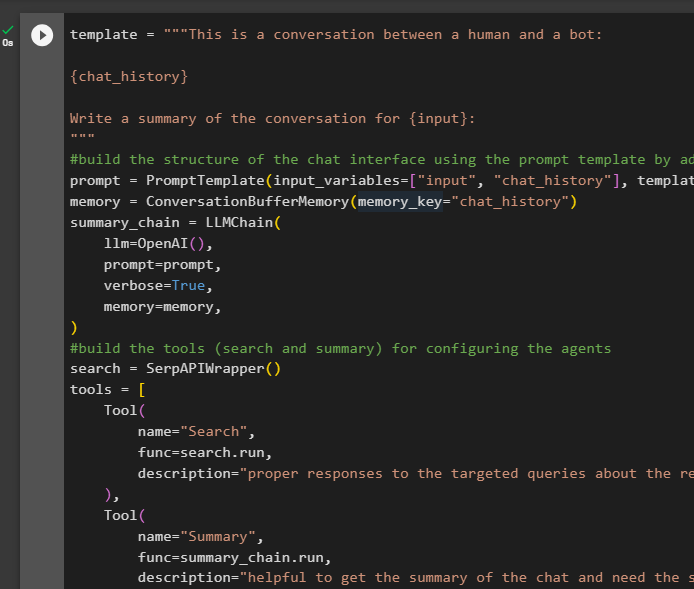
2. darbība: ķēdes pārbaude
Palaidiet šādu kodu:
aģenta_ķēde. palaist ( ievade = 'Kas ir LangChain' )Atbilde tiek veiksmīgi parādīta un saglabāta atmiņā:
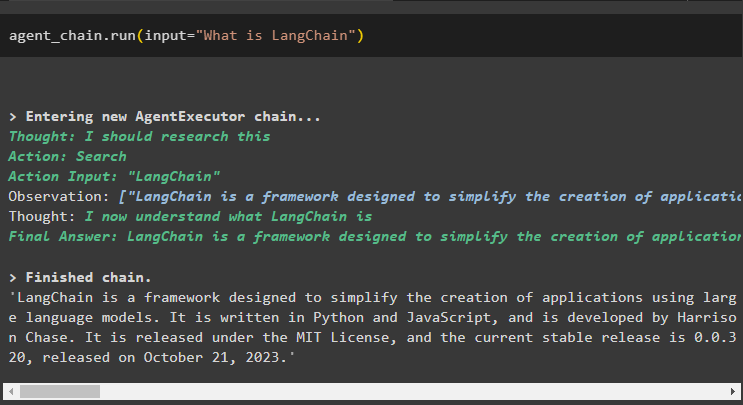
Uzdodiet papildu jautājumu, nesniedzot lielu daļu konteksta:
aģenta_ķēde. palaist ( ievade = 'Kas to izstrādāja?' )Aģents izmanto atmiņu, lai saprastu jautājumu, to pārveidojot, un pēc tam izdrukā atbildi:
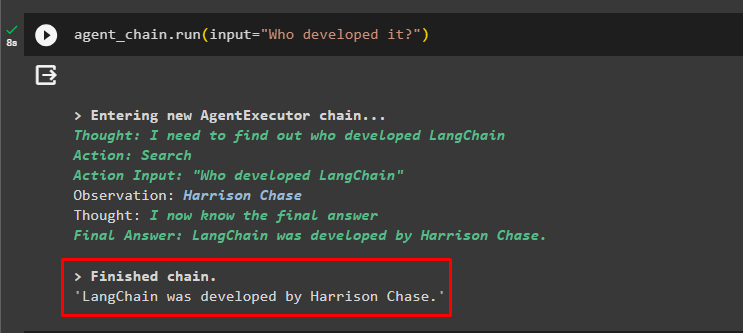
Iegūstiet tērzēšanas kopsavilkumu, izmantojot aģentam pievienoto atmiņu:
aģenta_ķēde. palaist (ievade = 'Paldies! Apkopojiet sarunu par manu 5 gadu vecumu'
)
Izvade
Kopsavilkums ir veiksmīgi izvilkts, un līdz šim viss šķiet pa vecam, taču izmaiņas notiek nākamajā solī:
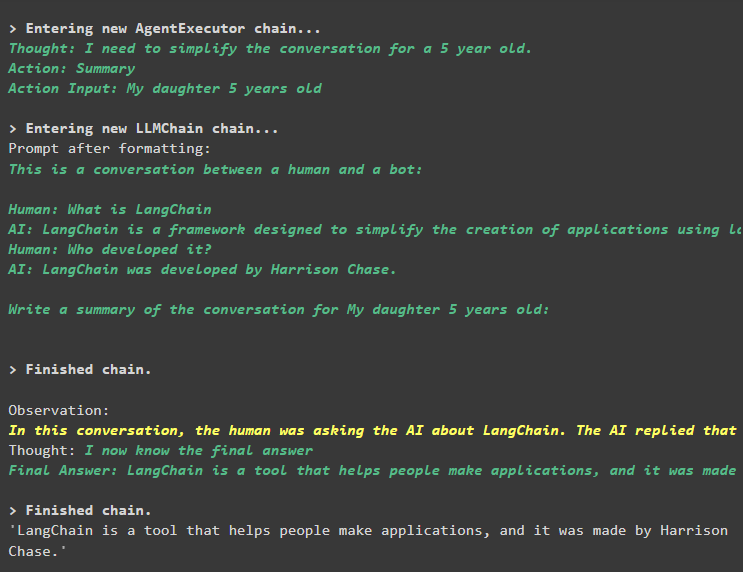
3. darbība. Atmiņas pārbaude
Tērzēšanas ziņojumu izvilkšana no atmiņas, izmantojot šādu kodu:
drukāt ( aģenta_ķēde. atmiņa . buferis )Rīks ir mainījis vēsturi, pievienojot vēl vienu jautājumu, kas sākotnēji netika uzdots. Tas notiek, kad modelis saprot jautājumu, izmantojot a pašam jautāt jautājums. Rīks kļūdaini domā, ka to jautā lietotājs, un uzskata to par atsevišķu vaicājumu. Tātad tas pievieno atmiņai arī šo papildu jautājumu, kas pēc tam tiks izmantots, lai iegūtu sarunas kontekstu:
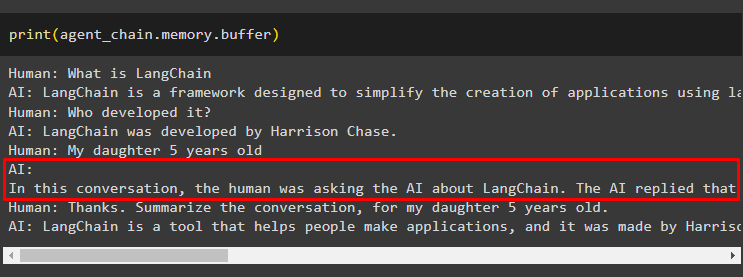
Tas pagaidām ir viss.
Secinājums
Lai programmā LangChain pievienotu atmiņu gan aģentam, gan tā rīkiem, instalējiet moduļus, lai iegūtu to atkarības un importētu no tiem bibliotēkas. Pēc tam izveidojiet sarunu atmiņu, valodas modeli, rīkus un aģentu, lai pievienotu atmiņu. The ieteicamā metode lai pievienotu atmiņu, aģentam izmanto ReadOnlyMemory un tā rīkus tērzēšanas vēstures saglabāšanai. Lietotājs var izmantot arī sarunu atmiņa gan aģentiem, gan instrumentiem. Bet viņi saņem apjucis dažreiz un mainīt tērzēšanu atmiņā.