Šajā rokasgrāmatā tiks ilustrēts atlases pēc maksimālās robežas atbilstības piemēra selektora izmantošanas process programmā LangChain.
Kā lietot Select by Maximal Marginal Relevance (MMR) programmā LangChain?
Maksimālās robežas atbilstības piemēra atlasītājs tiek izmantots, lai iegūtu informāciju, izmantojot uzvednes un piemēra kosinusa līdzību. Kosinusa līdzība tiek aprēķināta pēc iegulšanas metožu piemērošanas datiem un teksta pārvēršanas skaitliskā formā.
Lai uzzinātu, kā lietot MMR piemēru atlasītāju programmā LangChain, vienkārši veiciet norādītās darbības:
1. darbība: instalējiet moduļus
Sāciet procesu, instalējot LangChain atkarības, izmantojot komandu pip:
pip instalēt langchain
Instalējiet OpenAI moduli, lai izmantotu tā vidi OpenAIEMbedding() metodes lietošanai:
pip install openai
Instalējiet FAISS ietvaru, ko var izmantot, lai iegūtu izvadi, izmantojot semantisko līdzību:
pip instalēt faiss-gpu 
Tagad instalējiet tikttoken marķieri, lai sadalītu tekstu mazākos gabalos, izmantojot šādu kodu:
pip instalēt tiktoken 
2. darbība. Bibliotēku un piemēru izmantošana
Nākamais solis ir importēt bibliotēkas, lai izveidotu MMR piemēru atlasītāju, FAISS, OpenAIEmbeddings un PromptTemplate. Pēc bibliotēku importēšanas vienkārši izveidojiet piemēru kopu, kas sniedz ievades un izvades to attiecīgajām ievadēm vairākos masīvos:
no langchain. uzvednes . example_selector imports (MaxMarginalRelevanceExampleSelector ,
SemanticSimilarityExampleSelector ,
)
no langchain. vektoru veikali imports FAISS
no langchain. iegulšanas imports OpenAIEmbeddings
no langchain. uzvednes imports FewShotPromptTemplate , PromptTemplate
example_prompt = PromptTemplate (
ievades_mainīgie = [ 'ievade' , 'izeja' ] ,
veidne = 'Ievade: {input} \n Izvade: {output}' ,
)
piemēri = [
{ 'ievade' : 'laimīgs' , 'izeja' : 'skumji' } ,
{ 'ievade' : 'garš' , 'izeja' : 'īss' } ,
{ 'ievade' : 'enerģisks' , 'izeja' : 'letarģisks' } ,
{ 'ievade' : 'saulains' , 'izeja' : 'drūma' } ,
{ 'ievade' : 'vējš' , 'izeja' : 'mierīgs' } ,
]
3. darbība. Ēkas piemēru atlasītājs
Tagad sāciet veidot MMR piemēru atlasītāju, izmantojot MaxMarginalRelevanceExampleSelector() metodi, kas satur dažādus parametrus:
example_selector = MaxMarginalRelevanceExampleSelector. from_examples (piemēri ,
OpenAIEmbeddings ( ) ,
FAISS ,
k = 2 ,
)
mmr_prompt = FewShotPromptTemplate (
example_selector = example_selector ,
example_prompt = example_prompt ,
priedēklis = 'Piešķiriet katras ievades antonīmu' ,
piedēklis = 'Ievade: {īpašības vārds} \n Izvade:' ,
ievades_mainīgie = [ 'īpašības vārds' ] ,
)
4. darbība. MMR piemēra atlasītāja pārbaude
Pārbaudiet maksimālās robežas atbilstības MMR piemēru atlasītāju, izsaucot to print() metodē ar ievadi:
drukāt ( mmr_prompt. formātā ( īpašības vārds = 'uztraucies' ) ) 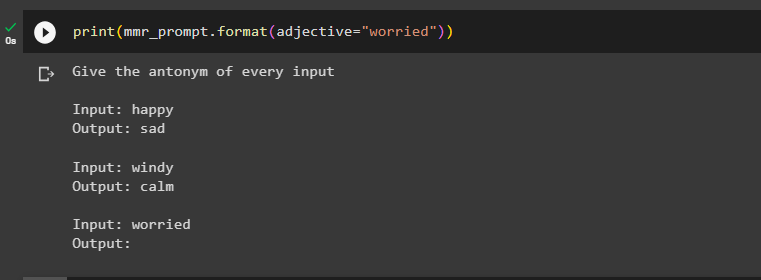
5. darbība. SemanticSimilarity izmantošana
Šajā darbībā tiek izmantota metode SemanticSimilarityExampleSelector() un pēc tam tiek izmantota metode FewShotPromptTemplate(), ko atbalsta LangChain:
example_selector = SemanticSimilarityExampleSelector. from_examples (piemēri ,
OpenAIEmbeddings ( ) ,
FAISS ,
k = 2 ,
)
līdzīga_uzvedne = FewShotPromptTemplate (
example_selector = example_selector ,
example_prompt = example_prompt ,
priedēklis = 'Piešķiriet katras ievades antonīmu' ,
piedēklis = 'Ievade: {īpašības vārds} \n Izvade:' ,
ievades_mainīgie = [ 'īpašības vārds' ] ,
)
drukāt ( līdzīga_uzvedne. formātā ( īpašības vārds = 'uztraucies' ) )
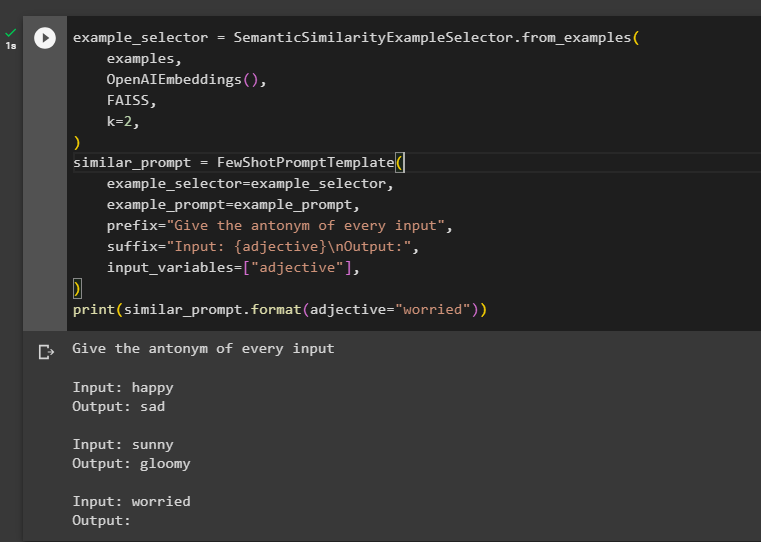
Tas viss attiecas uz atlases pēc maksimālās robežas atbilstības vai MMR izmantošanu programmā LangChain.
Secinājums
Lai lietotu Select by Maximal Marginal Relevance vai MMR piemēru atlasītāju programmā LangChain, instalējiet nepieciešamos moduļus. Pēc tam importējiet bibliotēkas, lai izveidotu piemēru kopu, izmantojot ievades un izvades uzvednes veidni. Izveidojiet MMR piemēra atlasītāju, lai to pārbaudītu, izmantojot MMR piemēru atlasītāju un FewShotPromptTemplate() metodi, lai iegūtu atbilstošu izvadi. Šajā rokasgrāmatā ir ilustrēts process, kā izmantot atlases pēc MMR piemēru atlasītāju programmā LangChain.