Šī rokasgrāmata ilustrēs sarunas kopsavilkuma izmantošanas procesu LangChain.
Kā lietot sarunu kopsavilkumu programmā LangChain?
LangChain nodrošina tādas bibliotēkas kā ConversationSummaryMemory, kas var iegūt pilnīgu tērzēšanas vai sarunas kopsavilkumu. To var izmantot, lai iegūtu galveno sarunas informāciju, nelasot visas tērzēšanā pieejamās ziņas un tekstu.
Lai uzzinātu sarunu kopsavilkuma lietošanas procesu programmā LangChain, vienkārši veiciet šādas darbības:
1. darbība: instalējiet moduļus
Vispirms instalējiet LangChain sistēmu, lai iegūtu tās atkarības vai bibliotēkas, izmantojot šādu kodu:
pip instalēt langchain
Tagad instalējiet OpenAI moduļus pēc LangChain instalēšanas, izmantojot komandu pip:
pip install openai 
Pēc moduļu uzstādīšanas vienkārši iekārtot vidi izmantojot šo kodu pēc API atslēgas iegūšanas no OpenAI konta:
imports tuimports getpass
tu . aptuveni [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API atslēga:' )
2. darbība. Sarunas kopsavilkuma izmantošana
Sāciet izmantot sarunas kopsavilkumu, importējot bibliotēkas no LangChain:
no langchain. atmiņa imports ConversationSummaryMemory , ChatMessageHistoryno langchain. llms imports OpenAI
Konfigurējiet modeļa atmiņu, izmantojot ConversationSummaryMemory() un OpenAI() metodes, un saglabājiet tajā datus:
atmiņa = ConversationSummaryMemory ( llm = OpenAI ( temperatūra = 0 ) )atmiņa. save_context ( { 'ievade' : 'Sveiki' } , { 'izeja' : 'Sveiki' } )
Palaidiet atmiņu, zvanot uz load_memory_variables() metode datu izvilkšanai no atmiņas:
atmiņa. load_memory_variables ( { } ) 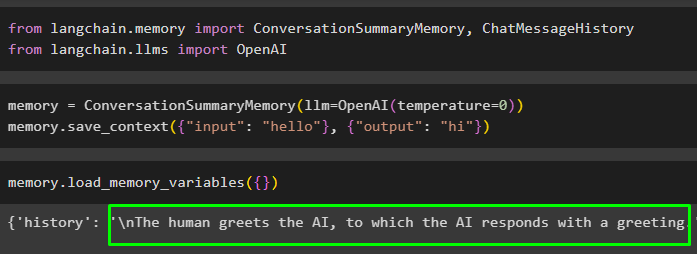
Lietotājs var arī iegūt datus sarunas veidā, piemēram, katra entītija ar atsevišķu ziņojumu:
atmiņa = ConversationSummaryMemory ( llm = OpenAI ( temperatūra = 0 ) , return_messages = Taisnība )atmiņa. save_context ( { 'ievade' : 'Sveiki' } , { 'izeja' : 'Čau, kā tev iet' } )
Lai iegūtu AI un cilvēku ziņojumu atsevišķi, izpildiet metodi load_memory_variables():
atmiņa. load_memory_variables ( { } ) 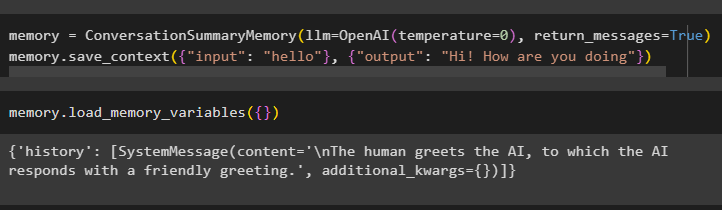
Saglabājiet sarunas kopsavilkumu atmiņā un pēc tam izpildiet atmiņu, lai ekrānā parādītu tērzēšanas/sarunas kopsavilkumu:
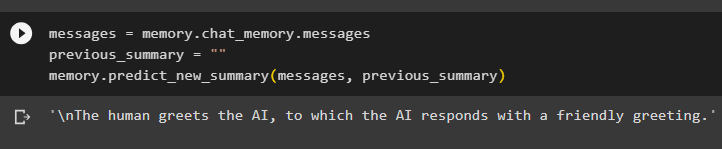
ziņas = atmiņa. tērzēšanas_atmiņa . ziņasIepriekšējais_kopsavilkums = ''
atmiņa. prognozēt_jauns_kopsavilkums ( ziņas , Iepriekšējais_kopsavilkums )
3. darbība. Sarunas kopsavilkuma izmantošana ar esošajiem ziņojumiem
Lietotājs var iegūt arī ārpus klases vai tērzēšanas sarunas kopsavilkumu, izmantojot ziņojumu ChatMessageHistory(). Šos ziņojumus var pievienot atmiņai, lai tā varētu automātiski ģenerēt visas sarunas kopsavilkumu:
vēsture = ChatMessageHistory ( )vēsture. add_user_message ( 'Sveiki' )
vēsture. add_ai_message ( 'Sveiki!' )
Izveidojiet modeli, piemēram, LLM, izmantojot OpenAI() metodi, lai izpildītu esošos ziņojumus tērzēšanas_atmiņa mainīgais:
atmiņa = ConversationSummaryMemory. from_Messages (llm = OpenAI ( temperatūra = 0 ) ,
tērzēšanas_atmiņa = vēsture ,
return_messages = Taisnība
)
Izpildiet atmiņu, izmantojot buferi, lai iegūtu esošo ziņojumu kopsavilkumu:
atmiņa. buferis 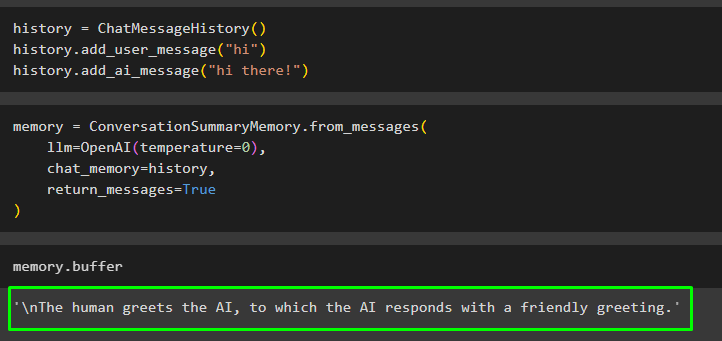
Izpildiet šo kodu, lai izveidotu LLM, konfigurējot buferatmiņu, izmantojot tērzēšanas ziņojumus:
atmiņa = ConversationSummaryMemory (llm = OpenAI ( temperatūra = 0 ) ,
buferis = '''Cilvēks jautā jautājumu mašīnai par sevi
Sistēma atbild, ka mākslīgais intelekts ir veidots uz labu, jo tas var palīdzēt cilvēkiem sasniegt savu potenciālu''' ,
tērzēšanas_atmiņa = vēsture ,
return_messages = Taisnība
)
4. darbība. Sarunas kopsavilkuma izmantošana ķēdē
Nākamajā darbībā ir izskaidrots sarunu kopsavilkuma izmantošanas process ķēdē, izmantojot LLM:
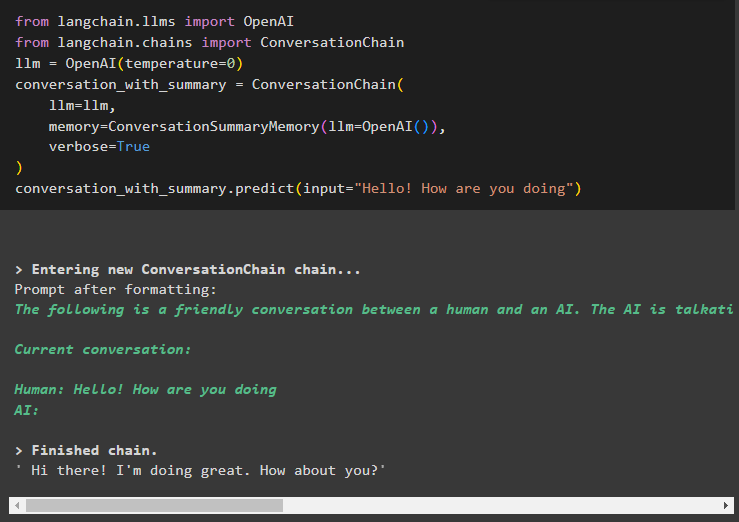
no langchain. llms imports OpenAIno langchain. ķēdes imports Sarunu ķēde
llm = OpenAI ( temperatūra = 0 )
saruna_ar_kopsavilkumu = Sarunu ķēde (
llm = llm ,
atmiņa = ConversationSummaryMemory ( llm = OpenAI ( ) ) ,
runīgs = Taisnība
)
saruna_ar_kopsavilkumu. prognozēt ( ievade = 'Sveiks, kā tev iet' )
Šeit mēs esam sākuši veidot ķēdes, uzsākot sarunu ar pieklājīgu aptauju:
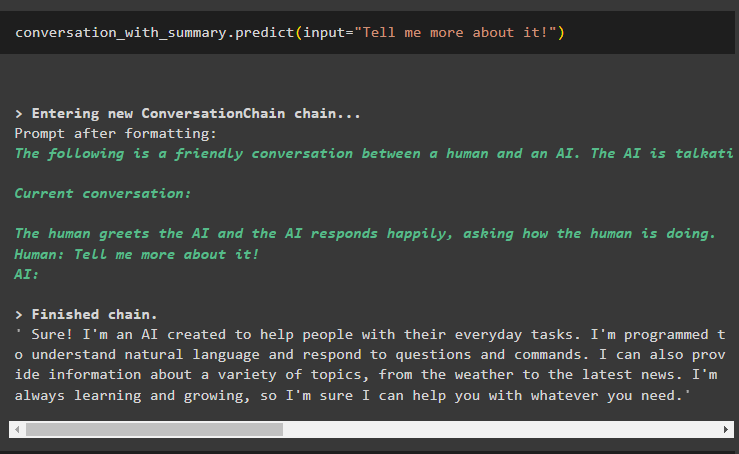
Tagad ieejiet sarunā, pajautājot mazliet vairāk par pēdējo rezultātu, lai to paplašinātu:
saruna_ar_kopsavilkumu. prognozēt ( ievade = — Pastāsti man par to vairāk! )Modelis ir izskaidrojis pēdējo ziņojumu ar detalizētu ievadu AI tehnoloģijā vai tērzēšanas robotā:
Izņemiet interesējošo punktu no iepriekšējās izvades, lai sarunu virzītu noteiktā virzienā:
saruna_ar_kopsavilkumu. prognozēt ( ievade = 'Pārsteidzoši Cik labs ir šis projekts?' )Šeit mēs saņemam detalizētas atbildes no robota, izmantojot sarunu kopsavilkuma atmiņas bibliotēku:
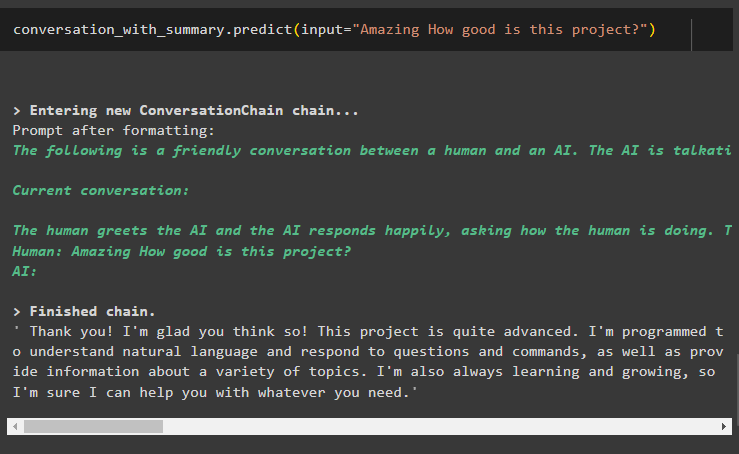
Tas ir viss par sarunas kopsavilkuma izmantošanu programmā LangChain.
Secinājums
Lai izmantotu sarunas kopsavilkuma ziņojumu programmā LangChain, vienkārši instalējiet moduļus un ietvarus, kas nepieciešami vides iestatīšanai. Kad vide ir iestatīta, importējiet ConversationSummaryMemory bibliotēka, lai izveidotu LLM, izmantojot OpenAI() metodi. Pēc tam vienkārši izmantojiet sarunas kopsavilkumu, lai no modeļiem iegūtu detalizētu rezultātu, kas ir iepriekšējās sarunas kopsavilkums. Šajā rokasgrāmatā ir detalizēti aprakstīts sarunu kopsavilkuma atmiņas izmantošanas process, izmantojot LangChain moduli.