Šī ziņa ilustrē metodi, kā izmantot izvades parsētāja funkcijas un klases, izmantojot LangChain sistēmu.
Kā izmantot izvades parsētāju, izmantojot LangChain?
Izvades parsētāji ir izejas un klases, kas var palīdzēt iegūt strukturētu izvadi no modeļa. Lai uzzinātu izvades parsētāju lietošanas procesu programmā LangChain, vienkārši veiciet norādītās darbības:
1. darbība: instalējiet moduļus
Pirmkārt, sāciet izvades parsētāju lietošanas procesu, instalējot LangChain moduli ar tā atkarībām, lai veiktu procesu:
pip uzstādīt langchain
Pēc tam instalējiet OpenAI moduli, lai izmantotu tā bibliotēkas, piemēram, OpenAI un ChatOpenAI:
pip uzstādīt openai
Tagad iestatiet vide OpenAI izmantojot API atslēgu no OpenAI konta:
importē mūs
importēt getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API atslēga:' )
2. darbība. Importējiet bibliotēkas
Nākamais solis ir bibliotēku importēšana no LangChain, lai sistēmā izmantotu izvades parsētājus:
no langchain.prompts importējiet HumanMessagePromptTemplate
no pydantic importa lauka
no langchain.prompts importējiet ChatPromptTemplate
no langchain.output_parsers importējiet PydanticOutputParser
no pydantic import BaseModel
no pydantic importa validatora
no langchain.chat_models importējiet ChatOpenAI
no langchain.llms importēt OpenAI
no ierakstīšanas importēšanas saraksts
3. darbība: izveidojiet datu struktūru
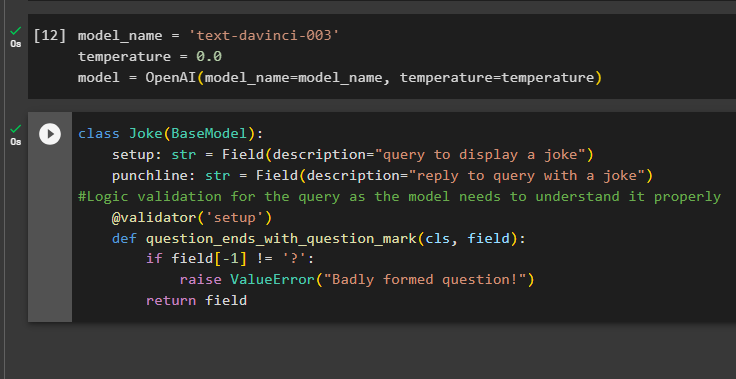
Izvades struktūras veidošana ir būtisks izvades parsētāju pielietojums lielos valodu modeļos. Pirms pāriet pie modeļu datu struktūras, ir jādefinē modeļa nosaukums, kuru mēs izmantojam, lai iegūtu strukturētu izvadi no izvades parsētājiem:
temperatūra = 0,0
modelis = OpenAI ( modeļa_nosaukums =modeļa_nosaukums, temperatūra = temperatūra )
Tagad izmantojiet Joke klasi, kurā ir BaseModel, lai konfigurētu izvades struktūru, lai iegūtu joku no modeļa. Pēc tam lietotājs var viegli pievienot pielāgotu validācijas loģiku, izmantojot pydantic klasi, kas var lūgt lietotājam ievietot labāk veidotu vaicājumu/uzvedni:
klases Joks ( Pamatmodelis ) :iestatīšana: str = lauks ( apraksts = 'vaicājums, lai parādītu joku' )
punchline: str = lauks ( apraksts = 'atbildēt uz vaicājumu ar joku' )
#Vaicājuma loģiskā validācija, jo modelim tas ir pareizi jāsaprot
@ validators ( 'uzstādīt' )
def jautājums_beidzas_ar_jautājuma_zīmi ( cls, lauks ) :
ja lauks [ - 1 ] ! = '?' :
paaugstināt ValueError ( 'Slikti izveidots jautājums!' )
atgriezties lauks
4. darbība: uzvednes veidnes iestatīšana
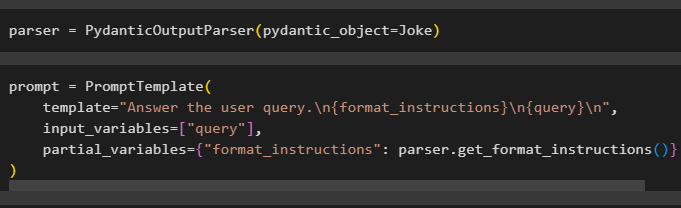
Konfigurējiet parsētāja mainīgo, kurā ir PydanticOutputParser() metode un tās parametri:
Pēc parsētāja konfigurēšanas vienkārši definējiet uzvednes mainīgo, izmantojot metodi PromptTemplate() ar vaicājuma/uzvednes struktūru:
prompt = PromptTemplate (veidne = 'Atbildiet uz lietotāja vaicājumu. \n {format_instructions} \n {query} \n ' ,
ievades_mainīgie = [ 'vaicājums' ] ,
daļēji_mainīgie = { 'format_instrukcijas' : parser.get_format_instructions ( ) }
)
5. darbība: pārbaudiet izvades parsētāju
Pēc visu prasību konfigurēšanas izveidojiet mainīgo, kas tiek piešķirts, izmantojot vaicājumu, un pēc tam izsauciet format_prompt() metodi:
_input = prompt.format_prompt ( vaicājums =joka_vaicājums )
Tagad izsauciet funkciju model (), lai definētu izvades mainīgo:
izvade = modelis ( _input.to_string ( ) )Pabeidziet testēšanas procesu, izsaucot metodi parser() ar izvades mainīgo kā parametru:
parsētājs.parsēt ( izvade ) 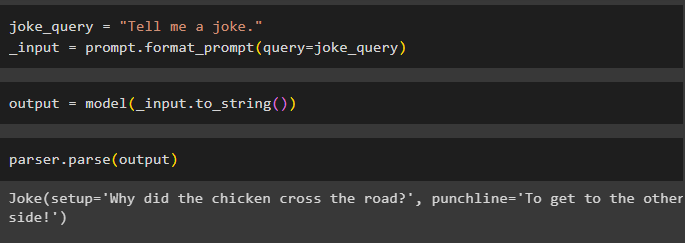
Tas ir viss par izvades parsētāja izmantošanas procesu LangChain.
Secinājums
Lai izmantotu izvades parsētāju programmā LangChain, instalējiet moduļus un iestatiet OpenAI vidi, izmantojot tās API atslēgu. Pēc tam definējiet modeli un pēc tam konfigurējiet izvades datu struktūru ar lietotāja nodrošināto vaicājuma loģisko validāciju. Kad datu struktūra ir konfigurēta, vienkārši iestatiet uzvednes veidni un pēc tam pārbaudiet izvades parsētāju, lai iegūtu rezultātu no modeļa. Šajā rokasgrāmatā ir ilustrēts izvades parsētāja izmantošanas process LangChain sistēmā.