Sintakse:
Hugging Face piedāvā dažādus pakalpojumus, taču viens no tā plaši izmantotajiem pakalpojumiem ir “API”. API ļauj mijiedarboties ar iepriekš apmācītu AI un lielu valodu modeļus dažādām lietojumprogrammām. Hugging Face nodrošina API dažādiem modeļiem, kā norādīts tālāk.
- Teksta ģenerēšanas modeļi
- Tulkošanas modeļi
- Sentimentu analīzes modeļi
- Virtuālo aģentu (inteliģento tērzēšanas robotu) izstrādes modeļi
- Klasifikācija un regresijas modeļi
Tagad atklāsim metodi, kā iegūt mūsu personalizēto secinājumu API no Hugging Face. Lai to izdarītu, mums vispirms ir jāreģistrējas oficiālajā Hugging Face vietnē. Pievienojieties šai Hugging Face kopienai, reģistrējoties šajā vietnē ar saviem akreditācijas datiem.
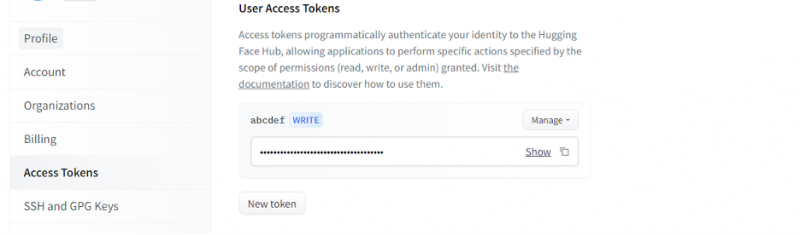
Kad esam ieguvuši kontu Hugging Face, mums tagad ir jāpieprasa secinājumu API. Lai pieprasītu API, atveriet konta iestatījumus un atlasiet “Piekļuves pilnvara”. Tiks atvērts jauns logs. Atlasiet opciju 'Jauns marķieris' un pēc tam ģenerējiet marķieri, vispirms norādot marķiera nosaukumu un tā lomu kā 'WRITE'. Tiek ģenerēts jauns marķieris. Tagad mums ir jāsaglabā šis marķieris. Līdz šim brīdim mums ir mūsu žetons no Hugging Face. Nākamajā piemērā mēs redzēsim, kā mēs varam izmantot šo marķieri, lai iegūtu secinājumu API.
1. piemērs. Kā izveidot prototipu, izmantojot Hugging Face Inference API
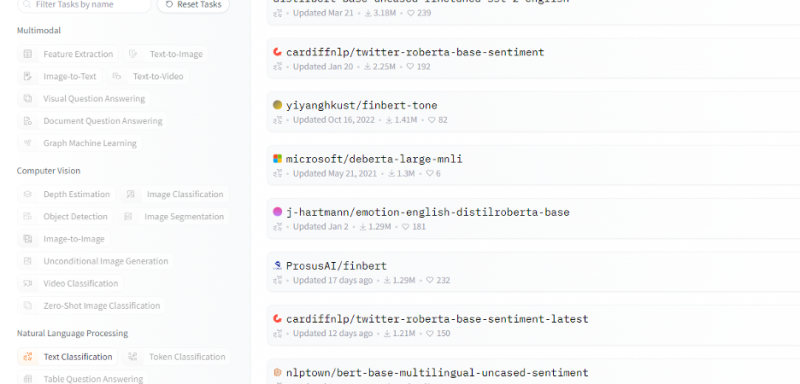
Līdz šim mēs apspriedām metodi, kā sākt lietot Hugging Face, un inicializējām Hugging Face marķieri. Šis piemērs parāda, kā mēs varam izmantot šo tikko ģenerēto marķieri, lai iegūtu secinājumu API konkrētam modelim (mašīnmācība) un veiktu prognozes, izmantojot to. Hugging Face mājaslapā atlasiet jebkuru modeli, ar kuru vēlaties strādāt un kas atbilst jūsu problēmai. Pieņemsim, ka mēs vēlamies strādāt ar teksta klasifikāciju vai noskaņojuma analīzes modeli, kā parādīts šajā šo modeļu saraksta fragmentā:
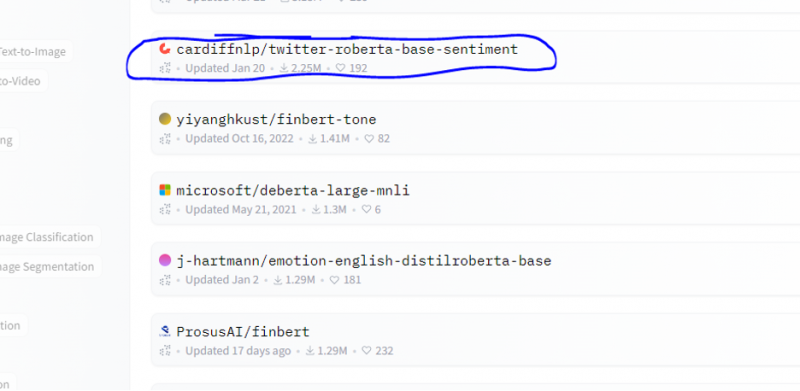
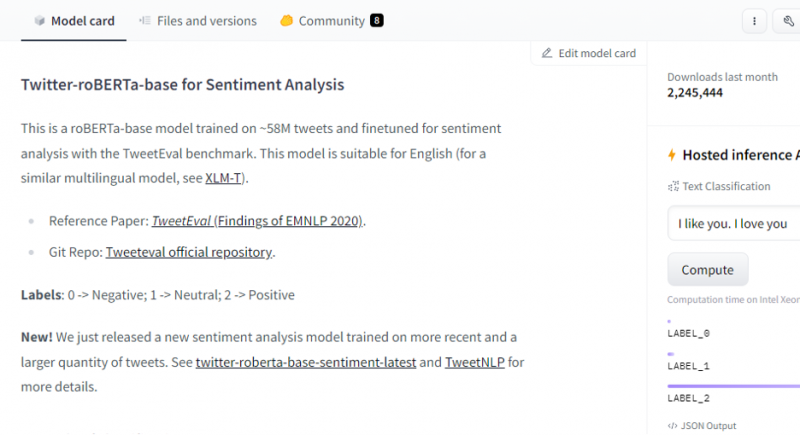
No šī modeļa mēs izvēlamies noskaņojuma analīzes modeli.
Pēc modeļa izvēles parādīsies tā modeļa karte. Šajā modeļa kartē ir informācija par modeļa apmācību un modeļa īpašībām. Mūsu modelis ir roBERTa-base, kas ir apmācīts 58M tvītos sentimenta analīzei. Šim modelim ir trīs galvenās klases etiķetes, un tas klasificē katru ievadi attiecīgajās klases etiķetēs.
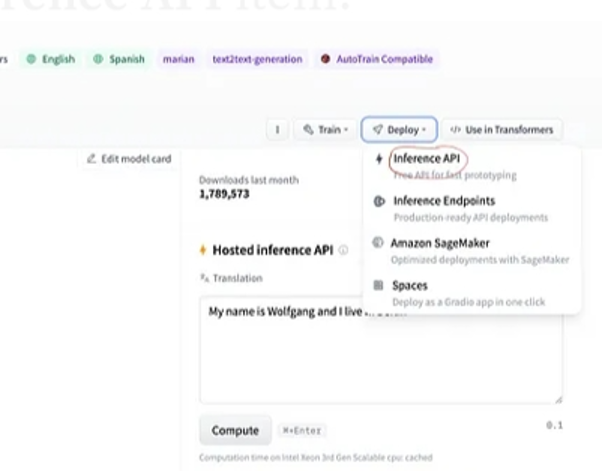
Ja pēc modeļa atlases atlasām izvietošanas pogu, kas atrodas loga augšējā labajā stūrī, tiek atvērta nolaižamā izvēlne. Šajā izvēlnē mums ir jāizvēlas opcija “Inference API”.
Pēc tam secinājumu API sniedz pilnīgu skaidrojumu par to, kā izmantot šo konkrēto modeli ar šo secinājumu, un ļauj mums ātri izveidot AI modeļa prototipu. Secinājumu API logā tiek parādīts kods, kas rakstīts Python skriptā.
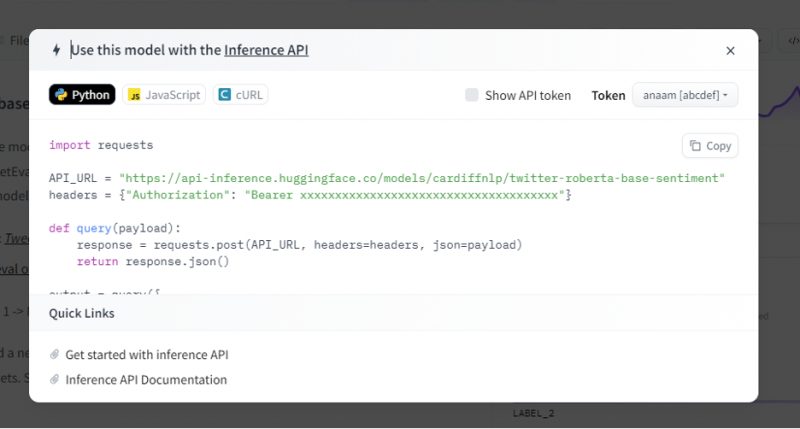
Mēs nokopējam šo kodu un izpildām šo kodu jebkurā Python IDE. Šim nolūkam mēs izmantojam Google Colab. Pēc šī koda izpildīšanas Python čaulā tas atgriež izvadi, kas tiek piegādāta kopā ar rezultātu un etiķetes prognozi. Šī etiķete un rezultāts tiek piešķirts saskaņā ar mūsu ievadi, jo mēs izvēlējāmies 'teksta sentimenta analīzes' modeli. Pēc tam ievade, ko mēs piešķiram modelim, ir pozitīvs teikums, un modelis tika iepriekš apmācīts trīs iezīmju klasēs: etiķete 0 nozīmē negatīvu, etiķete 1 nozīmē neitrālu un etiķete 2 ir iestatīta uz pozitīvu. Tā kā mūsu ievade ir pozitīvs teikums, modeļa prognoze ir lielāka nekā pārējās divas etiķetes, kas nozīmē, ka modelis paredzēja teikumu kā “pozitīvu”.
imports pieprasījumusAPI_URL = 'https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment'
galvenes = { 'Autorizācija' : 'Nesējs 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' }
def vaicājums ( kravnesība ) :
atbildi = pieprasījumus. pastu ( API_URL , galvenes = galvenes , json = kravnesība )
atgriezties atbildi. json ( )
izvade = vaicājums ( {
'ievades' : 'Es jūtos labi, kad tu esi ar mani' ,
} )
Izvade:

2. piemērs: Apkopošanas modelis, izmantojot secinājumus
Mēs veicam tās pašas darbības, kas parādītas iepriekšējā piemērā, un prototipējam kopsavilkuma modeļa kopni, izmantojot tā secinājumu API no Hugging Face. Kopsavilkuma modelis ir iepriekš apmācīts modelis, kas apkopo visu tekstu, ko mēs tam piešķiram kā ievadi. Dodieties uz Hugging Face kontu, noklikšķiniet uz modeļa augšējā izvēlņu joslā un pēc tam izvēlieties modeli, kas atbilst kopsavilkumam, atlasiet to un uzmanīgi izlasiet tā modeļa karti.
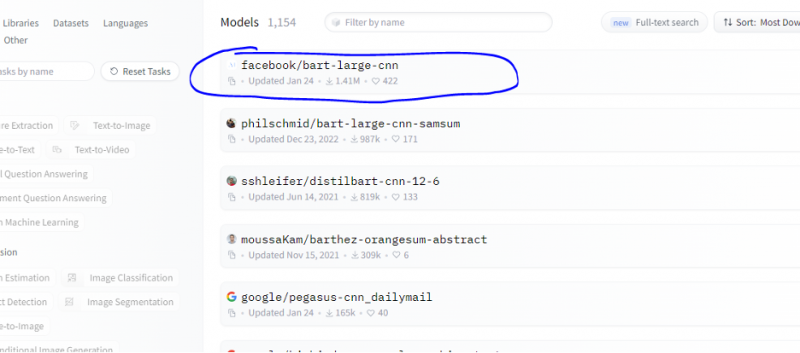
Mūsu izvēlētais modelis ir iepriekš apmācīts BART modelis, un tas ir precīzi pielāgots datu kopai CNN pasta pasts. BART ir modelis, kas visvairāk līdzinās BERT modelim, kuram ir kodētājs un dekodētājs. Šis modelis ir efektīvs, ja tas ir precīzi noregulēts izpratnes, kopsavilkuma, tulkošanas un teksta ģenerēšanas uzdevumiem.
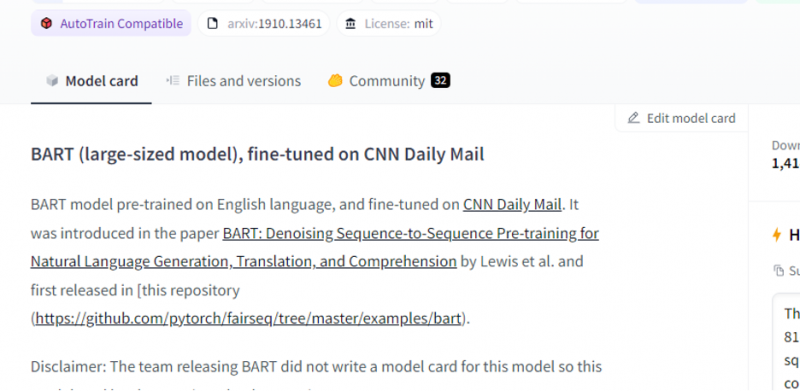
Pēc tam augšējā labajā stūrī izvēlieties pogu “Izvietošana” un nolaižamajā izvēlnē atlasiet secinājumu API. Secinājumu API atver citu logu, kurā ir kods un norādījumi, kā izmantot šo modeli ar šo secinājumu.
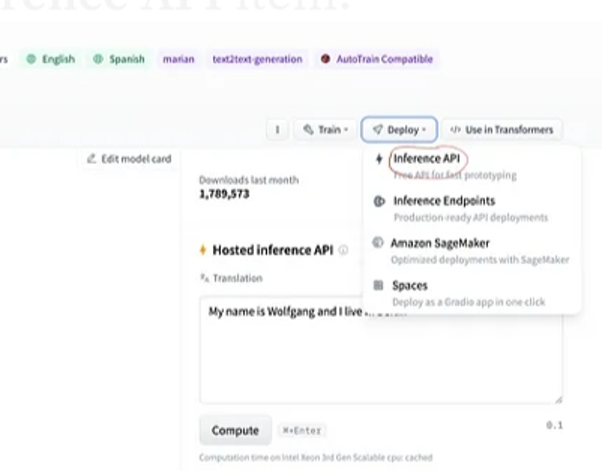
Nokopējiet šo kodu un izpildiet to Python čaulā.
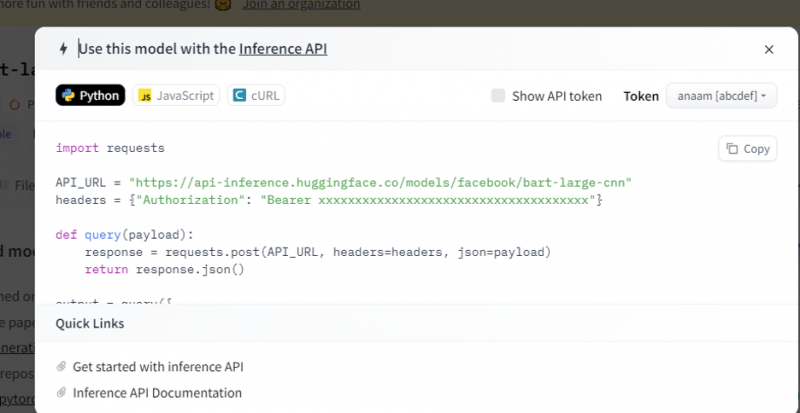
Modelis atgriež izvadi, kas ir tam ievadītās ievades kopsavilkums.

Secinājums
Mēs strādājām pie Hugging Face Inference API un uzzinājām, kā mēs varam izmantot šīs lietojumprogrammas programmējamo saskarni, lai strādātu ar iepriekš apmācītiem valodu modeļiem. Divi piemēri, ko mēs izdarījām rakstā, galvenokārt balstījās uz NLP modeļiem. Hugging Face API var radīt brīnumus, ja vēlamies izstrādāt ātru prototipu, nodrošinot ātru AI modeļu integrāciju mūsu lietojumprogrammās. Īsāk sakot, Hugging Face piedāvā risinājumus visām jūsu problēmām, sākot no pastiprināšanas mācībām līdz datorredzei.