Šajā rakstā tiks apspriests, kā izmantot Elasticsearch multi-get API, lai iegūtu vairākus JSON dokumentus, pamatojoties uz to ID. Turklāt Elasticsearch ļauj izmantot vienu iegūšanas vaicājumu, lai izgūtu dokumentus no indeksiem, izmantojot tikai dokumentu ID.
Izpētīsim.
Pieprasīt sintakse
Tālāk ir norādīta Elasticsearch multi-get API sintakse:
GET /_mget
GET /
Multi-get API atbalsta vairākus indeksus, kas ļauj ienest dokumentus pat tad, ja tie nav vienā indeksā.
Pieprasījums atbalsta šādus ceļa parametrus:
-
– Indeksa nosaukums, no kura izgūt dokumentus, kā norādīts to ID.
Varat arī norādīt citus vaicājuma parametrus, kā parādīts:
- Priekšroka – Definē vēlamo mezglu vai fragmentu.
- Īsts laiks – Ja iestatīts uz True, darbība tiek veikta reāllaikā.
- atjaunot – Pirms norādīto dokumentu izgūšanas piespiež operāciju atsvaidzināt mērķa lauskas.
- Maršrutēšana – Vērtība, kas tiek izmantota, lai novirzītu darbības uz noteiktu fragmentu.
- Store_fields – Izgūst dokumenta laukus, kas saglabāti rādītājā, nevis dokumentā.
- _avots – Būla vērtība, kas nosaka, vai pieprasījumam ir jāatgriež lauks _source vai nē.
Vaicājumam ir nepieciešams pamatteksts, kas ietver šādas vērtības:
- Dokumenti – Norāda dokumentus, kurus vēlaties ienest. Turklāt šī sadaļa atbalsta šādus atribūtus:
- _id – mērķa dokumenta unikālais ID.
- _index – indekss, kas satur mērķa dokumentu.
- Maršrutēšana – Dokumenta primārās šķembas atslēga.
- _avots – Ja patiess, tas ietver visus avota laukus; pretējā gadījumā tas tos izslēdz.
- _stored_fields – saglabātie_lauki, kurus vēlaties iekļaut.
- Ids - to dokumentu ID, kurus vēlaties ienest.
1. piemērs: ienesiet vairākus dokumentus no viena rādītāja
Šajā piemērā parādīts, kā izmantot Elasticsearch multi-get API, lai no Netflix indeksa izgūtu dokumentus ar noteiktiem ID:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: ziņošana' -H 'Satura veids: lietojumprogramma/json' -d'{
'dokumenti': [
{
'_id': 'T3wnVoMBck2AezXPytlJ'
},
{
'_id': 'W3wnVoMBck2AezXPytlJ'
}
]
}'
Dotajam pieprasījumam ir jāienes dokumenti ar norādītajiem ID no Netflix indeksa. Iegūtais rezultāts ir šāds:
{'dokumenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'atrasts': patiess,
'_avots': {
'ilgums': '90 min',
'listed_in': 'Dokumentālās filmas',
'valsts': 'Amerikas Savienotās Valstis',
'date_added': '2021. gada 25. septembris',
'show_id': 's1',
'režisors': 'Kirstena Džonsone',
'release_year': 2020,
'vērtējums': 'PG-13',
'apraksts': 'Kad viņas tēvs tuvojas mūža beigām, filmas veidotāja Kirstena Džonsone inscenē savu nāvi izdomātā un komiskā veidā, lai palīdzētu viņiem abiem stāties pretī neizbēgamajam.'
'tips': 'Filma',
'title': 'Diks Džonsons ir miris'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AezXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'atrasts': patiess,
'_avots': {
'valsts': 'Vācija, Čehija',
'show_id': 's13',
'režisors': 'Christian Schwochow',
'release_year': 2021,
'vērtējums': 'TV-MA',
'apraksts': 'Pēc tam, kad teroristu sprādzienā tiek noslepkavota lielākā daļa viņas ģimenes, jauna sieviete tiek neapzināti vilināta pievienoties tai grupai, kas viņu nogalināja.'
'tips': 'Filma',
'title': 'Es esmu Kārlis',
'ilgums': '127 min',
'listed_in': 'Drāmas, starptautiskās filmas',
'lomas': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Viktor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '2021. gada 23. septembris'
}
}
]
}
Mēs varam arī vienkāršot pieprasījumu, ievietojot dokumentu ID vienkāršā masīvā, kā parādīts tālāk.
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: ziņošana' -H 'Satura veids: lietojumprogramma/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Iepriekšējam pieprasījumam ir jāveic līdzīga darbība.
2. piemērs: ienesiet dokumentus no vairākām indikācijām
Šajā piemērā pieprasījums ienes vairākus dokumentus no dažādiem indeksiem, kā parādīts:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: ziņošana' -H 'Satura veids: lietojumprogramma/json' -d'{
'dokumenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ'
},
{
'_index': 'disnejs',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Iegūtais rezultāts ir šāds:

3. piemērs: izslēdziet konkrētus laukus
Mēs varam izslēgt konkrētus laukus no konkrētā pieprasījuma, izmantojot parametrus source_include un source_exclude.
Piemērs ir šāds:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: ziņošana' -H 'Satura veids: lietojumprogramma/json' -d'{
'dokumenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_source': nepatiess
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AezXPytlJ',
'_avots': {
'include': [ 'listed_in', 'release_year', 'title' ],
'izslēgt': [ 'apraksts', 'tips', 'pievienošanas datums']
}
}
]
}'
Dotais pieprasījums izmanto avota iekļaušanu un izslēgšanu, lai norādītu, kurus laukus vēlaties izgūt konkrētajā dokumentā.
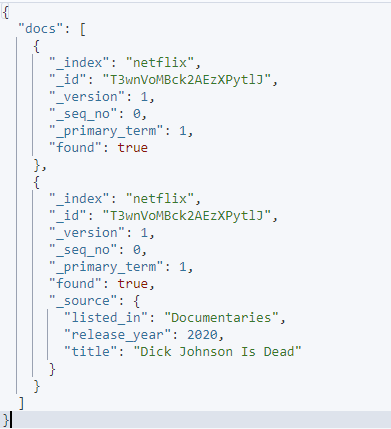
Iegūtais rezultāts ir šāds:
Secinājums
Šajā ziņojumā mēs apspriedām pamatus darbam ar Elasticsearch multi-get API, kas ļauj iegūt vairākus dokumentus no dažādiem avotiem, pamatojoties uz to ID. Lai iegūtu plašāku informāciju, lūdzu, izpētiet citus dokumentus.
Laimīgu kodēšanu!