Dublēti dati bieži var radīt neskaidrības, kļūdas un šķību ieskatu. Par laimi, Google izklājlapas sniedz mums daudz rīku un paņēmienu, lai vienkāršotu šo lieko ierakstu identificēšanu un noņemšanu. Sākot no pamata šūnu salīdzinājumiem līdz uzlabotām, uz formulām balstītām pieejām, jūs būsiet aprīkots, lai pārblīvētas lapas pārveidotu sakārtotos, vērtīgos resursos.
Neatkarīgi no tā, vai apstrādājat klientu sarakstus, aptauju rezultātus vai jebkuru citu datu kopu, ierakstu dublikātu novēršana ir būtisks solis ceļā uz uzticamu analīzi un lēmumu pieņemšanu.
Šajā rokasgrāmatā mēs apskatīsim divas metodes, kas ļauj identificēt un noņemt dublētās vērtības.
Tabulas izveide
Vispirms mēs izveidojām tabulu Google izklājlapās, kas tiks izmantota turpmākajos šī raksta piemēros. Šai tabulai ir 3 kolonnas: A slejā ar galveni “Nosaukums” tiek saglabāti nosaukumi; B kolonnai ir virsraksts “Vecums”, kurā ir norādīti cilvēku vecumi; un visbeidzot, C slejā, virsraksts “Pilsēta”, ir ietvertas pilsētas. Ja mēs novērojam, daži ieraksti šajā tabulā tiek dublēti, piemēram, ieraksti “Jānis” un “Sāra”.
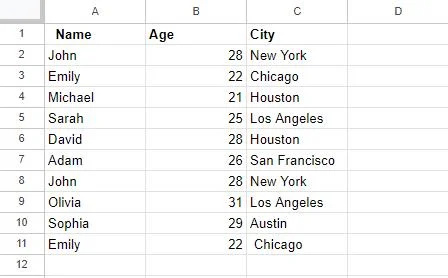
Mēs strādāsim pie šīs tabulas, lai noņemtu šīs dublētās vērtības ar dažādām metodēm.
1. metode: Google izklājlapu funkcijas “Noņemt dublikātus” izmantošana
Pirmā metode, par kuru mēs šeit runājam, ir dublēto vērtību noņemšana, izmantojot Google izklājlapas funkciju “Noņemt dublikātus”. Šī metode neatgriezeniski noņems dublētos ierakstus no atlasītā šūnu diapazona.
Lai parādītu šo metodi, mēs vēlreiz apsvērsim iepriekš izveidoto tabulu.
Lai sāktu strādāt pie šīs metodes, vispirms mums ir jāatlasa viss diapazons, kurā ir mūsu dati, tostarp galvenes. Šajā scenārijā mēs esam izvēlējušies šūnas A1:C11 .
Google izklājlapu loga augšdaļā redzēsit navigācijas joslu ar dažādām izvēlnēm. Atrodiet un noklikšķiniet uz opcijas “Dati” navigācijas joslā.
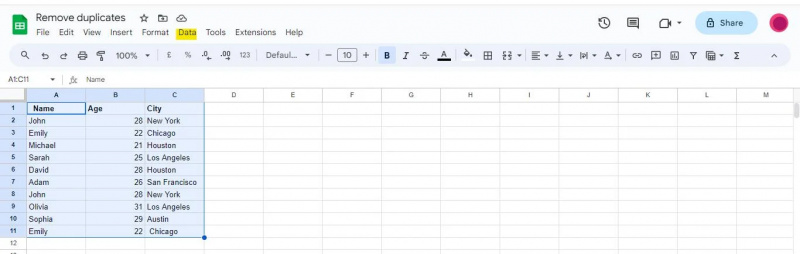
Noklikšķinot uz opcijas “Dati”, tiks parādīta nolaižamā izvēlne, kas piedāvā dažādus ar datiem saistītus rīkus un funkcijas, ko var izmantot datu analīzei, tīrīšanai un manipulēšanai.
Šajā piemērā mums būs jāpiekļūst izvēlnei “Dati”, lai pārietu uz opciju “Datu tīrīšana”, kas ietver funkciju “Noņemt dublikātus”.
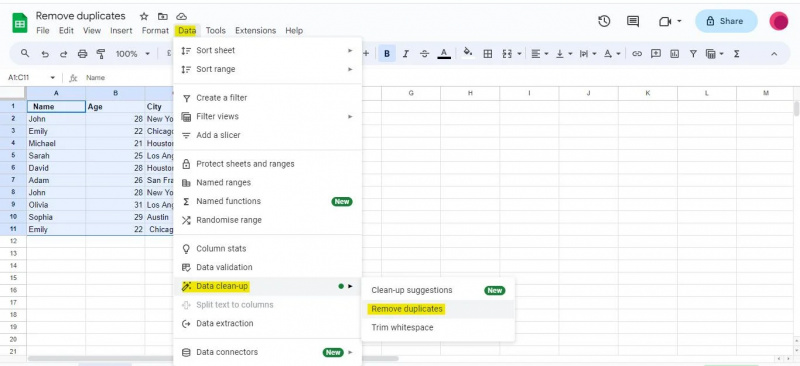
Kad būsim piekļuvuši dialoglodziņam “Noņemt dublikātus”, mums tiks parādīts mūsu datu kopas kolonnu saraksts. Pamatojoties uz šīm kolonnām, tiks atrasti un noņemti dublikāti. Mēs atzīmēsim atbilstošās izvēles rūtiņas dialoglodziņā atkarībā no tā, kuras kolonnas vēlamies izmantot dublikātu identificēšanai.
Mūsu piemērā ir trīs kolonnas: “Vārds”, “Vecums” un “Pilsēta”. Tā kā mēs vēlamies identificēt dublikātus, pamatojoties uz visām trim kolonnām, esam atzīmējuši visas trīs izvēles rūtiņas. Turklāt, ja jūsu tabulā ir galvenes, jums ir jāatzīmē izvēles rūtiņa “Datiem ir galvenes rinda”. Tā kā iepriekš sniegtajā tabulā ir galvenes, esam atzīmējuši izvēles rūtiņu Datiem ir galvenes rinda.
Kad esam atlasījuši kolonnas, lai identificētu dublikātus, mēs varam turpināt noņemt šos dublikātus no mūsu datu kopas.
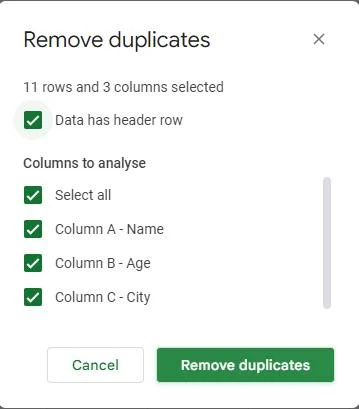
Dialoglodziņa “Noņemt dublikātus” apakšā ir poga ar nosaukumu “Noņemt dublikātus”. Noklikšķiniet uz šīs pogas.
Pēc noklikšķināšanas uz “Noņemt dublikātus” Google izklājlapas apstrādās jūsu pieprasījumu. Kolonnas tiks pārbaudītas, un visas rindas ar vērtību dublikātiem šajās kolonnās tiks noņemtas, veiksmīgi novēršot dublikātus.
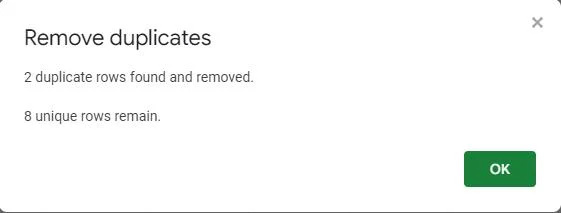
Uznirstošais ekrāns apstiprina, ka dublētās vērtības ir noņemtas no tabulas. Tas parāda, ka tika atrastas un noņemtas divas dublētās rindas, atstājot tabulu ar astoņiem unikāliem ierakstiem.
Pēc funkcijas “Noņemt dublikātus” izmantošanas mūsu tabula tiek atjaunināta šādi:
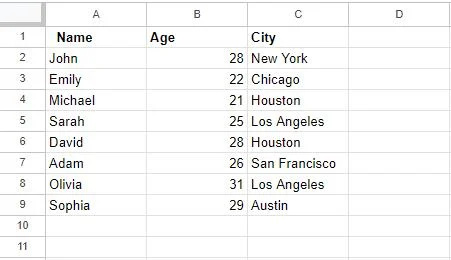
Šeit jāņem vērā svarīga piezīme, ka dublikātu noņemšana, izmantojot šo līdzekli, ir pastāvīga darbība. Dublētās rindas tiks dzēstas no jūsu datu kopas, un jūs nevarēsit atsaukt šo darbību, ja vien jums nebūs datu dublējuma. Tāpēc pārliecinieties, vai esat izvēlējies pareizās slejas, lai atrastu dublikātus, vēlreiz pārbaudot atlasi.
2. metode: UNIKĀLĀS funkcijas izmantošana dublikātu noņemšanai
Otrā metode, par kuru mēs šeit runāsim, ir izmantot UNIKĀLS funkcija Google izklājlapās. The UNIKĀLS funkcija izgūst atšķirīgas vērtības no noteikta datu diapazona vai kolonnas. Lai gan tas tieši nenoņem dublikātus no sākotnējiem datiem, tas izveido unikālu vērtību sarakstu, ko varat izmantot datu pārveidošanai vai analīzei bez dublikātiem.
Izveidosim piemēru, lai saprastu šo metodi.
Mēs izmantosim tabulu, kas tika ģenerēta šīs apmācības sākotnējā daļā. Kā mēs jau zinām, tabulā ir noteikti dati, kas tiek dublēti. Tātad, mēs esam izvēlējušies šūnu “E2”, lai rakstītu UNIKĀLS formulu. Mūsu uzrakstītā formula ir šāda:
=UNIKĀLS(A2:A11)
Izmantojot Google izklājlapās, unikālā formula izgūst unikālas vērtības atsevišķā kolonnā. Tātad, mēs esam nodrošinājuši šo formulu ar diapazonu no šūnas A2 uz A11 , kas tiks lietota A slejā. Tādējādi šī formula izņem unikālās vērtības no kolonnas A un parāda tos kolonnā, kurā ir rakstīta formula.
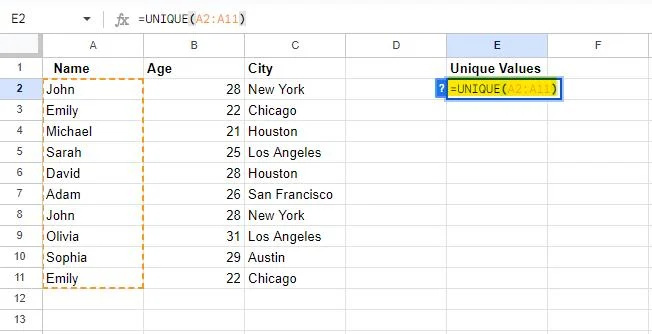
Formula tiks piemērota norādītajam diapazonam, nospiežot taustiņu Enter.
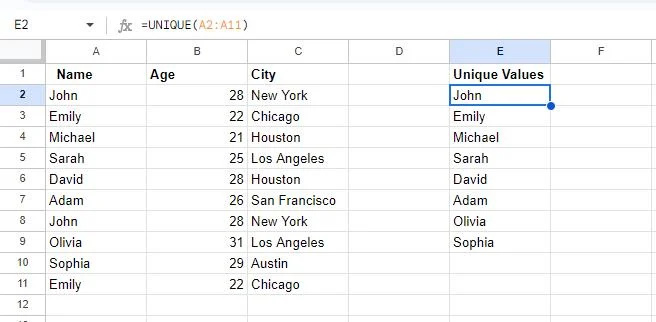
Šajā momentuzņēmumā redzams, ka divas šūnas ir tukšas. Tas ir tāpēc, ka tabulā ir dublētas divas vērtības, proti, Džons un Emīlija. The UNIKĀLS funkcija parāda tikai vienu katras vērtības gadījumu.
Izmantojot šo metodi, dublētās vērtības netika noņemtas tieši no norādītās kolonnas, bet tika izveidota cita kolonna, lai sniegtu mums šīs kolonnas unikālos ierakstus, novēršot dublikātus.
Secinājums
Dublikātu noņemšana pakalpojumā Google izklājlapas ir izdevīga datu analīzes metode. Šajā rokasgrāmatā ir parādītas divas metodes, kas ļauj viegli noņemt dublētos ierakstus no saviem datiem. Pirmā metode izskaidroja Google izklājlapu izmantošanu, lai noņemtu dublikātu. Šī metode skenē norādīto šūnu diapazonu un novērš dublikātus. Otra mūsu apspriestā metode ir izmantot formulu dublēto vērtību izgūšanai. Lai gan tas tieši nenoņem dublikātus no diapazona, tā vietā tiek parādītas unikālās vērtības jaunā kolonnā.